Satoshi Kondo, Daisuke Miyakawa, Kengo Shiraki, Miki Suga, Teppei Usuki 13 May 2020
Misreporting of financial information (‘falsification of financial statements’) is a serious economic event that should be avoided both from a practical point of view and because of potential damage arising from corporate accounting scandals.
The misreporting of listed firms’ financial information, in particular, distorts the decision-making of various economic entities involved in financial transactions such as stocks, bond trading, and bank lending, which introduces inefficient resource allocation. In real business relationships, such misreporting may also lead to excessive risk-taking that neither the customer nor the supplier are aware of. Consequently, when this risk becomes apparent, unintended stagnation of economic activities may result. If misreporting is intentional (‘accounting fraud’) and occurs frequently, even more serious consequences such as market breakdowns may occur.
Research on fraudulent accounting mechanisms has so far been mainly theoretical and conducted to a large extent in the accounting field (e.g. Dechow et al. 1996). One strand of the theoretical literature focuses on potential ‘reasons’ for a firm to commit accounting fraud. Discussed reasons for a company to intentionally falsify financial information are, for example, the attempt to realise better procurement terms when facing sluggish business performance. Such studies usually describe the optimal behaviour of a company given certain objective functions and constraints, hence specifying the determinants of accounting fraud.
The second strand of the theoretical literature seeks to identify financial information that is statistically correlated with the occurrence of accounting fraud.
A large number of studies have looked at, for example, ‘discretionary accounting accruals’. Those are thought to be linked to management's profit adjustment behaviour and are found to be strongly correlated with accounting fraud.
In recent years, progress has been made in the empirical literature which uses statistical models to detect accounting fraud in financial statements and thus identifies companies that are likely to engage in fraudulent behaviour. In empirical studies, Dechow et al. (2011) and Song et al. (2016) incorporate the independent variables accounting for accounting fraud into parametric models to detect a concurrent event. These models exhibit a good in-sample fit and also confirm the theoretical conjecture.
While the empirical literature has made good progress in detecting accounting fraud, there is still a large number of variables yet to be considered. Including only few variables into a model, while helpful for testing theoretical hypotheses, neglects a vast amount of information about companies which might bring additional prediction power.
Our goal in Kondo et al. (2019) is hence to incorporate a large number of explanatory variables into a model that detects accounting fraud using machine learning methods (a type of random forest developed in Chen et al. 2004). As discussed in two well-known recent articles (Perols 2011, Perols et al. 2017), detecting accounting fraud is like searching for a needle in a haystack. Our model uses the broadest possible swath of corporate information such as financial indicators constructed from corporate financial information; corporate governance-related variables, with a focus on the shareholder, executive and employee information; and bank transaction variables based on banking information as explanatory variables.
A second goal of our model is to address the occurrence of future accounting fraud, or ‘forecasting’. Most of the existing research focuses explicitly on the detection of accounting fraud in current statements (‘nowcasting’), which, unlike for example a bankruptcy event, is not necessarily easily observable to the public. Hence, ‘nowcasting’ has great practical value for auditing. From the viewpoint of the audit business, it would also be prudent to specifically screen companies where misreporting is more likely to occur. Thus, we use our machine learning-based analysis framework to forecast accounting fraud.
We verify the performance of our forecasting model as follows.1 Using account fraud information from the data on publicly listed companies in Japan, we compared the performance of different models. Model 1 is a parametric model that relies only on limited variables used in existing research. Model 2 is a non-parametric model that uses machine learning and relies only on limited variables and model 3-16 are non-parametric models using machine learning with an expanding set of variables. Model 12, specifically, is a complete model relying on all variables described above.
First, we find that both the use of machine learning techniques and high-dimensional feature space improves detection performance (Figure 1). Since the expansion of variables in model 12 is possible only with the use of machine learning, it is not easy to measure how much the application of machine learning methods versus expansion of the variable space actually contributed to the better fraud detection performance. The results suggest there is room for ingenuity when it comes to the methods of constructing a detection model even when using a variable group similar to that of existing research.
Figure 1 Performance evaluation results

Note: Figure 1 shows AUC, a performance evaluation indicator, of all the detection models trained using Accounting Fraud Flags 2 (i.e. serious and ancillary events), and scored on the test data, together with its 95% confidence interval. See Kondo et al. (2019) for more detail.
We validate the performance of our model with respect to our second goal of forecasting using a hold-out sample (Figure 2). We confirm that our model achieves a sufficient forecasting performance. Hence, we add to the literature by showing that it is worthwhile to use a machine learning model with high-dimensional data to forecast future accounting fraud.
Figure 2 Performance evaluation results with respect to forecasting

Note: Figure 2 shows AUC, a performance evaluation indicator, of all the prediction models trained using Accounting Fraud Flags 2 (i.e. serious and ancillary events), and scored on the test data, together with its 95% confidence interval. See Kondo et al. (2019) for more detail.
We also show that other variables besides those used in existing research can be useful, at least to a certain degree. Specifically, the average length of employee service and the percentage of outstanding shares held by company executives rank high in terms of degree of importance. We demonstrate in Figure 3 how the estimated forecast score fluctuates with these variables. The results imply that there may be many other variables that contribute significantly to detecting and forecasting fraud besides those considered in the literature so far. Hence, our results indicate that there is room for these model to be of more practical use if the feature space is expanded while also calling for further theoretical research of accounting fraud mechanisms.
Figure 3 Relationship between attribute changes in the vicinity of average attributes and changes in score
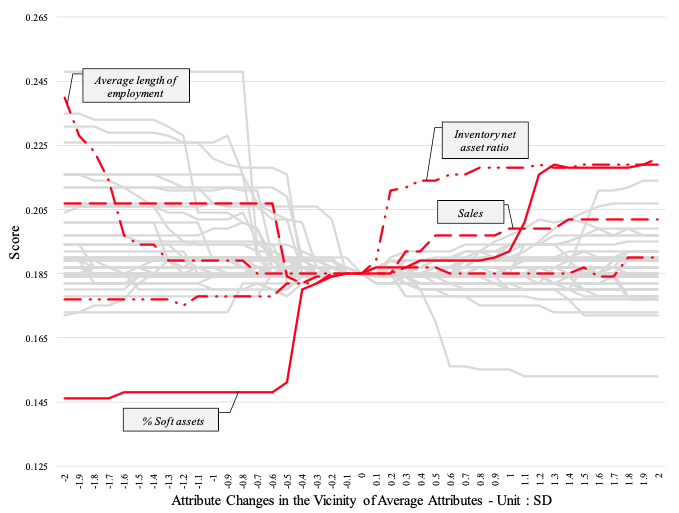
Note: Figure 3 illustrates changes in the score when each attribute is changed either upward or downward.
It should be noted that the construction of the machine learning-based model requires the establishment of various hyperparameters, especially in the training step. Some examples include the number of trees to be constructed, the minimum number of branches, and the type of statistics referred to in setting the branching rules. While the results we are, for the most part, not dependent on these parameters, it is necessary to point out that machine learning methods do not to automate all the tasks involved in model construction.
Further, it should be recognised that there are other machine learning methods to detect and predict accounting fraud apart from the one used in our paper. In fact, some of the authors of this study have achieved good performance using different machine learning methods, which suggests that a more robust model can be obtained in the future by combining scores of different models. Since it is obviously beneficial to build a compact and easy-to-use model, future models can build on our study and limit the number of variables used to those that we find to be relatively important from a prediction point of view. However, one should note that even if the target outcomes are the same, different variables rank highly in importance depending on whether the goal is detecting or forecasting fraud. Additionally, even when performing the same forecast, different target flag settings can cause differences in the variable groups that rank highly. Thus, variable selection should be conducted in accordance with the purpose of the model when building such a compact and easy-to-use model.
Another caveat is that our predictive model assumes constant socio-economic environments and accounting standards. For example, if there is a completely different kind of fraud in a new business, the current model may not be able to detect or forecast this. Moreover, even if the realities of a company remain the same, financial variables may take different values due to changes in accounting standards, which may affect fraud detection and fraud forecast results. Thus, it is important to regularly monitor the effectiveness of the model.
Once a satisfactory predictive model has been built, the resulting score has to be analysed and adequate reactions need to be decided on. Since there are companies that are currently committing accounting fraud or that are likely to commit it the near future, professional staff with specialised knowledge need to handle such cases promptly. Good judgement is needed to establish when the probability of accounting fraud is substantial enough to warrant interference. Related to this, account-level anomaly detection is an important research theme that complements our company-level fraudulent model. We should also note that there is a large concern regarding the extent to which the on-site professional staff use such scores when the model scores are provided. Thus, another potential issue is how to effectively incentivise the staff to take advantage of the high detection and prediction power of the scores (see the discussion in, for example, Kleinberg et al. 2018).
There is a further concern from a policy perspective over how to adopt such prediction technology. For example, if the details of a model for detecting fraudulent accounting become widely known, companies that are attempting some type of accounting fraud may be able to avoid detection. In reality, it is unlikely that the model details would become widely known, and it is hence not easy to commit fraud without being detected by the model. One possible solution for this problem would be to continuously improve models such that companies engaging in malicious efforts to bypass these models will find it harder to do so.
Another topic that needs further discussion when considering advanced measures to prevent accounting fraud is the question of whether it is even possible to suppress fraudulent events by adopting a specific audit approach or governance device.
Editor's note: The main research on which this column is based first appeared as a Discussion Paper of the Research Institute of Economy, Trade and Industry (RIETI) of Japan.
References
Chen, C, A Liaw and L Breiman (2004), “Using Random Forest to Learn Imbalanced Data”, Technical Report 666 Statistics Department of University of California at Berkley.
Dechow, P M, W Ge, C R Larson and R G Sloan (2011), “Predicting Material Accounting Misstatements”, Contemporary Accounting Research 28:17-82.
Dechow, P M, R G Sloan and A P Sweeney (1996), “Causes and Consequences of Earnings Manipulation: An Analysis of Firms Subject to Enforcement Actions by the SEC”, Contemporary Accounting Research 13:1-36.
Kleinberg, J, H Lakkaraju, J Leskovec, J Ludwig and S Mullainathan (2018), “Human Decisions and Machine Forecasts”, Quarterly Journal of Economics 133: 237-293.
Kondo, S, D Miyakawa, K Shiraki, M Suga and T Usuki (2019), “Using Machine Learning to Detect and Forecast Accounting Fraud”, RIETI Discussion Paper Series 19-E-103.
Perlos, J (2011), “Financial Statement Fraud Detection: An Analysis of Statistical and Machine Learning Algorithms”, Auditing: A Journal of Practice & Theory 30: 19-50.
Perlos, J, B Bowen and C Zimmerman (2017), “Finding Needles in a Haystack: Using Data Analytics to Improve Fraud Forecast”, Accounting Review 92: 221-245.
Song M, N Oshuro and A Shuto (2016), “Predicting Accounting Fraud: Evidence from Japan”, The Japanese Accounting Review 6: 17-63.
West, J and M Bhattacharya (2016), “Intelligent Financial Fraud Detection: A Comprehensive Review”, Computer & Security 57: 47-66.
Endnotes
1 See West and Bhattacharya (2016) for a survey of recent prediction and forecast model development trends targeting fraud (credit cards, securities, insurance) in the financial sector, including accounting fraud.
"machine" - Google News
May 13, 2020 at 06:02AM
https://ift.tt/2YWYBR1
Machine learning against accounting fraud | VOX, CEPR Policy Portal - voxeu.org
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Machine learning against accounting fraud | VOX, CEPR Policy Portal - voxeu.org"
Post a Comment