Historians interested in the way events and people were chronicled in the old days once had to sort through card catalogs for old papers, then microfiche scans, then digital listings — but modern advances can index them down to each individual word and photo. A new effort from the Library of Congress has digitized and organized photos and illustrations from centuries of news using state of the art machine learning.
Led by Ben Lee, a researcher from the University of Washington occupying the Library’s “Innovator in Residence” position, the Newspaper Navigator collects and surfaces data from images from some 16 million pages of newspapers throughout American history.
Lee and his colleagues were inspired by work already being done in Chronicling America, an ongoing digitization effort for old newspapers and other such print materials. While that work used optical character recognition to scan the contents of all the papers, there was also a crowd-sourced project in which people identified and outlined images for further analysis. Volunteers drew boxes around images relating to World War I, then transcribed the captions and categorized the picture.
This limited effort set the team thinking.
“I loved it because it emphasized the visual nature of the pages — seeing the visual diversity of the content coming out of the project, I just thought it was so cool, and I wondered what it would be like to chronicle content like this from all over America,” Lee told TechCrunch.
He also realized that what the volunteers had created was in fact an ideal set of training data for a machine learning system. “The question was, could we use this stuff to create an object detection model to go through every newspaper, to throw open the treasure chest?”
The answer, happily, was yes. Using the initial human-powered work of outlining images and captions as training data, they built an AI agent that could do so on its own. After the usual tweaking and optimizing, they set it loose on the full Chronicling America database of newspaper scans.
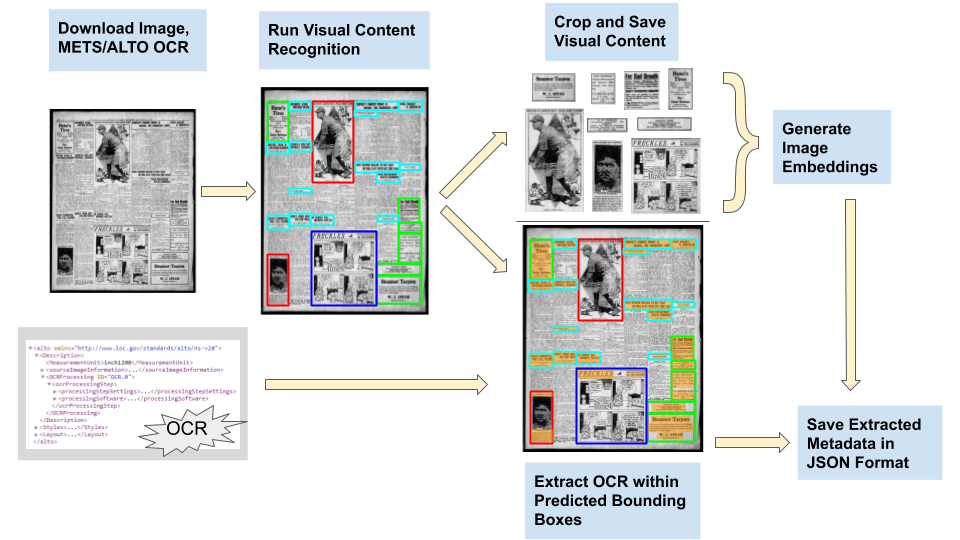
“It ran for 19 days nonstop — definitely the largest computing job I’ve ever run,” said Lee. But the results are remarkable: millions of images spanning three centuries (from 1789 to 1963) and organized with metadata pulled from their own captions. The team describes their work in a paper you can read here.
Assuming the captions are at all accurate, these images — until recently only accessible by trudging through the archives date by date and document by document — can be searched for their contents like any other corpus.
Looking for pictures of the president in 1870? No need to browse dozens of papers looking for potential hits and double-checking the contents in the caption — just search Newspaper Navigator for “president 1870.” Or if you want editorial cartoons from the World War II era, you can just get all illustrations from a date range. (The team has already zipped up the photos into yearly packages and plans other collections.)
Here are a few examples of newspaper pages with the machine learning system’s determinations overlaid on them (warning: plenty of hat ads and racism):
[gallery ids="1985834,1985828,1985829,1985830,1985833"]
That’s fun for a few minutes for casual browsers, but the key thing is what it opens up for researchers — and other sets of documents. The team is throwing a data jam today to celebrate the release of the dataset and tools, during which they hope to both discover and enable new applications.
“Hopefully it will be a great way to get people together to think of creative ways the dataset can be used,” said Lee. “The idea I’m really excited by from a machine learning perspective, is trying to build out a user interface where people can build their own dataset. Political cartoons or fashion ads, just let users define users they’re interested in and train a classifier based on that.”
In other words, Newspaper Navigator’s AI agent could be the parent for a whole brood of more specific ones that could be used to scan and digitize other collections. That’s actually the plan within the Library of Congress, where the digital collections team has been delighted by the possibilities brought up by Newspaper Navigator and machine learning in general.
“One of the things we’re interested in is how computation can expand the way we’re enabling search and discovery,” said Kate Zwaard. “Because we have OCR, you can find things it would have taken months or weeks to find. The Library’s book collection has all these beautiful plates and illustrations. But if you want to know like, what pictures are there of the Madonna and child, some are categorized, but others are inside books that aren’t catalogued.”
That could change in a hurry with an image-and-caption AI systematically poring over them.
Newspaper Navigator, the code behind it, and all the images and results from it are completely public domain, free to use or modify for any purpose. You can dive into the code at the project’s GitHub.
"machine" - Google News
May 08, 2020 at 01:38AM
https://ift.tt/2SLn3Rp
Millions of historic newspaper images get the machine learning treatment at the Library of Congress - TechCrunch
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Millions of historic newspaper images get the machine learning treatment at the Library of Congress - TechCrunch"
Post a Comment