In recent years, machines have become almost as good as humans, and sometimes better, in a wide range of abilities — for example, object recognition, natural language processing and diagnoses based on medical images.
And yet machines trained in this way still make mistakes that humans would never fall for. For example, small changes to an image, that a human would ignore, can force a machine to mislabel it entirely. That has potentially serious implications in applications on which human lives depend, such as medical diagnoses.
So computer scientists are desperate to understand the limitations of machine learning in more detail. Now a team made up largely of Google computer engineers have identified an entirely new weakness at the heart of the machine learning process that leads to these problems.
Known as underspecification, the team shows how it influences in a wide variety of machine learning applications, ranging from computer vision to medical genomics. And they say that machine learning protocols need to be revised to test for these shortcomings, particularly for real-world applications.
First, some background. Machine learning involves training a model with data so that it learns to spot or predict features. The Google team picks on the example of training a machine learning system to predict the course of a pandemic.
Pandemic Modeling
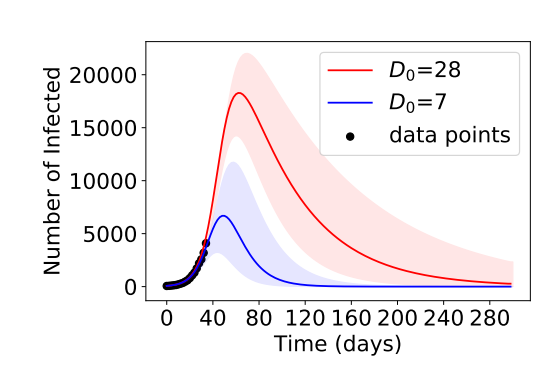
Epidemiologists have built detailed models of the way a disease spreads from infected individuals to susceptible individuals, but not to those who have recovered — and so are immune. Key factors in this spread are the rate of infection, often called R0, and length of time, D, that an infected individual is infectious.
Obviously, a disease can spread more widely when it is more infectious and when people are infectious for longer. However, the disease becomes less able to spread as more people recover, eventually building up herd immunity.
So an important task is to determine R0 and D early in the pandemic when the number of infections is growing rapidly. These parameters then define the course of the disease, including features such as peak number of infections and who this number drops gradually over time.
Epidemiologists desperately need to know this early in a pandemic since it determines when and if hospitals will become overwhelmed.
A machine learning model can help. It can simulate the progress of the pandemic by learning the parameters R0 and D from the data gathered early in the disease’s progression. Once these numbers are known, it can then predict the entire evolution of the disease.
But the Google team says these parameters are underspecified during the early stages of a pandemic. What they mean by this is that there are lots of pairs of the values, R0 and D, that accurately describe the same early exponential growth.
However, these pairs can lead to dramatically different predictions later. “When used to forecast the trajectory of the epidemic, these parameters yield very different predictions,” say the team.
The problem arises because the machine learning process has no way to properly choose between these pairs. Indeed, the Google team goes on to show that the parameters the machine chooses can depend on entirely arbitrary decisions in the way the model is set up.
Public health officials can avoid the problem of underspecification by constraining the problem with additional information such as real measurements of how long patients are infectious, which influences D, and the contact patterns within the population, which influences R0.
This is a relatively simple example but a key finding from the Google team is that underspecification occurs in many other situations too. “In general, the solution to a problem is underspecified if there are many distinct solutions that solve the problem equivalently,” they say. But these solutions do not all make the same predictions.
Real Scenarios
The team goes on to show how underspecification occurs in a surprisingly wide range of real deep learning scenarios. These include medical image analysis, clinical diagnoses based on electronic health records and natural language processing.
The Google team shows that small changes, such as modifying the random seeds used in training, can force a model towards an entirely different solution and so lead to different predictions. They also show how this can cause the models to inherit biases in the data set that have nothing to do with prediction task they are undertaking.
What’s more, the problem is likely to be much more widespread than the Google team has found. Their goal was simply to detect underspecification, rather than fully characterize it. So they are likely to have underestimated its prevalence. “The extreme complexity of modern machine learning models ensures that some aspect of the model will almost certainly be underspecified,” they say.
If these aspects can be spotted in advance, there are various ways of tackling underspecification. One is to design “stress tests” to see how well a model performs on real-world data and to pick up potential problems.
However, this requires a good understanding of the way the model can go wrong. “Designing stress tests that are well-matched to applied requirements, and that provide good “coverage" of potential failure modes is a major challenge,” says the team.
That’s interesting work revealing an important and previously unappreciated Achille’s Heel in machine learning. It places important limitations on the credibility of machine learning predictions and may we’ll force some rethinking over certain applications. Special attention will be needed, particularly where machine learning is part of systems linked to human welfare, such as self-driving cars and medical imaging.
In these scenarios, relatively small blind spots in machine learning capabilities could have life and death implications.
Ref: Underspecification Presents Challenges for Credibility in Modern Machine Learning: arxiv.org/abs/2011.03395
"machine" - Google News
December 01, 2020 at 12:43AM
https://ift.tt/3mpw67h
Google Reveals Major Hidden Weakness In Machine Learning - Discover Magazine
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Google Reveals Major Hidden Weakness In Machine Learning - Discover Magazine"
Post a Comment