Just when you thought it couldn’t grow any more explosively, the data/AI landscape just did: the rapid pace of company creation, exciting new product and project launches, a deluge of VC financings, unicorn creation, IPOs, etc.
It has also been a year of multiple threads and stories intertwining.
One story has been the maturation of the ecosystem, with market leaders reaching large scale and ramping up their ambitions for global market domination, in particular through increasingly broad product offerings. Some of those companies, such as Snowflake, have been thriving in public markets (see our MAD Public Company Index), and a number of others (Databricks, Dataiku, DataRobot, etc.) have raised very large (or in the case of Databricks, gigantic) rounds at multi-billion valuations and are knocking on the IPO door (see our Emerging MAD company Index).
But at the other end of the spectrum, this year has also seen the rapid emergence of a whole new generation of data and ML startups. Whether they were founded a few years or a few months ago, many experienced a growth spurt in the past year or so. Part of it is due to a rabid VC funding environment and part of it, more fundamentally, is due to inflection points in the market.
In the past year, there’s been less headline-grabbing discussion of futuristic applications of AI (self-driving vehicles, etc.), and a bit less AI hype as a result. Regardless, data and ML/AI-driven application companies have continued to thrive, particularly those focused on enterprise use trend cases. Meanwhile, a lot of the action has been happening behind the scenes on the data and ML infrastructure side, with entirely new categories (data observability, reverse ETL, metrics stores, etc.) appearing or drastically accelerating.
To keep track of this evolution, this is our eighth annual landscape and “state of the union” of the data and AI ecosystem — coauthored this year with my FirstMark colleague John Wu. (For anyone interested, here are the prior versions: 2012, 2014, 2016, 2017, 2018, 2019: Part I and Part II, and 2020.)
For those who have remarked over the years how insanely busy the chart is, you’ll love our new acronym: Machine learning, Artificial intelligence, and Data (MAD) — this is now officially the MAD landscape!
We’ve learned over the years that those posts are read by a broad group of people, so we have tried to provide a little bit for everyone — a macro view that will hopefully be interesting and approachable to most, and then a slightly more granular overview of trends in data infrastructure and ML/AI for people with a deeper familiarity with the industry.
Quick notes:
- My colleague John and I are early-stage VCs at FirstMark, and we invest very actively in the data/AI space. Our portfolio companies are noted with an (*) in this post.
Let’s dig in.
The macro view: Making sense of the ecosystem’s complexity
Let’s start with a high-level view of the market. As the number of companies in the space keeps increasing every year, the inevitable questions are: Why is this happening? How long can it keep going? Will the industry go through a wave of consolidation?
Rewind: The megatrend
Readers of prior versions of this landscape will know that we are relentlessly bullish on the data and AI ecosystem.
As we said in prior years, the fundamental trend is that every company is becoming not just a software company, but also a data company.
Historically, and still today in many organizations, data has meant transactional data stored in relational databases, and perhaps a few dashboards for basic analysis of what happened to the business in recent months.
But companies are now marching towards a world where data and artificial intelligence are embedded in myriad internal processes and external applications, both for analytical and operational purposes. This is the beginning of the era of the intelligent, automated enterprise — where company metrics are available in real time, mortgage applications get automatically processed, AI chatbots provide customer support 24/7, churn is predicted, cyber threats are detected in real time, and supply chains automatically adjust to demand fluctuations.
This fundamental evolution has been powered by dramatic advances in underlying technology — in particular, a symbiotic relationship between data infrastructure on the one hand and machine learning and AI on the other.
Both areas have had their own separate history and constituencies, but have increasingly operated in lockstep over the past few years. The first wave of innovation was the “Big Data” era, in the early 2010s, where innovation focused on building technologies to harness the massive amounts of digital data created every day. Then, it turned out that if you applied big data to some decade-old AI algorithms (deep learning), you got amazing results, and that triggered the whole current wave of excitement around AI. In turn, AI became a major driver for the development of data infrastructure: If we can build all those applications with AI, then we’re going to need better data infrastructure — and so on and so forth.
Fast-forward to 2021: The terms themselves (big data, AI, etc.) have experienced the ups and downs of the hype cycle, and today you hear a lot of conversations around automation, but fundamentally this is all the same megatrend.

The big unlock
A lot of today’s acceleration in the data/AI space can be traced to the rise of cloud data warehouses (and their lakehouse cousins — more on this later) over the past few years.
It is ironic because data warehouses address one of the most basic, pedestrian, but also fundamental needs in data infrastructure: Where do you store it all? Storage and processing are at the bottom of the data/AI “hierarchy of needs” — see Monica Rogati’s famous blog post here — meaning, what you need to have in place before you can do any fancier stuff like analytics and AI.
You’d figure that 15+ years into the big data revolution, that need had been solved a long time ago, but it hadn’t.
In retrospect, the initial success of Hadoop was a bit of a head-fake for the space — Hadoop, the OG big data technology, did try to solve the storage and processing layer. It did play a really important role in terms of conveying the idea that real value could be extracted from massive amounts of data, but its overall technical complexity ultimately limited its applicability to a small set of companies, and it never really achieved the market penetration that even the older data warehouses (e.g., Vertica) had a few decades ago.
Today, cloud data warehouses (Snowflake, Amazon Redshift, and Google BigQuery) and lakehouses (Databricks) provide the ability to store massive amounts of data in a way that’s useful, not completely cost-prohibitive, and doesn’t require an army of very technical people to maintain. In other words, after all these years, it is now finally possible to store and process big data.
That is a big deal and has proven to be a major unlock for the rest of the data/AI space, for several reasons.
First, the rise of data warehouses considerably increases market size not just for its category, but for the entire data and AI ecosystem. Because of their ease of use and consumption-based pricing (where you pay as you go), data warehouses become the gateway to every company becoming a data company. Whether you’re a Global 2000 company or an early-stage startup, you can now get started building your core data infrastructure with minimal pain. (Even FirstMark, a venture firm with several billion under management and 20-ish team members, has its own Snowflake instance.)
Second, data warehouses have unlocked an entire ecosystem of tools and companies that revolve around them: ETL, ELT, reverse ETL, warehouse-centric data quality tools, metrics stores, augmented analytics, etc. Many refer to this ecosystem as the “modern data stack” (which we discussed in our 2020 landscape). A number of founders saw the emergence of the modern data stack as an opportunity to launch new startups, and it is no surprise that a lot of the feverish VC funding activity over the last year has focused on modern data stack companies. Startups that were early to the trend (and played a pivotal role in defining the concept) are now reaching scale, including DBT Labs, a provider of transformation tools for analytics engineers (see our Fireside Chat with Tristan Handy, CEO of DBT Labs and Jeremiah Lowin, CEO of Prefect), and Fivetran, a provider of automated data integration solutions that streams data into data warehouses (see our Fireside Chat with George Fraser, CEO of Fivetran), both of which raised large rounds recently (see Financing section).
Third, because they solve the fundamental storage layer, data warehouses liberate companies to start focusing on high-value projects that appear higher in the hierarchy of data needs. Now that you have your data stored, it’s easier to focus in earnest on other things like real-time processing, augmented analytics, or machine learning. This in turn increases the market demand for all sorts of other data and AI tools and platforms. A flywheel gets created where more customer demand creates more innovation from data and ML infrastructure companies.
As they have such a direct and indirect impact on the space, data warehouses are an important bellwether for the entire data industry — as they grow, so does the rest of the space.
The good news for the data and AI industry is that data warehouses and lakehouses are growing very fast, at scale. Snowflake, for example, showed a 103% year-over-year growth in their most recent Q2 results, with an incredible net revenue retention of 169% (which means that existing customers keep using and paying for Snowflake more and more over time). Snowflake is targeting $10 billion in revenue by 2028. There’s a real possibility they could get there sooner. Interestingly, with consumption-based pricing where revenues start flowing only after the product is fully deployed, the company’s current customer traction could be well ahead of its more recent revenue numbers.
This could certainly be just the beginning of how big data warehouses could become. Some observers believe that data warehouses and lakehouses, collectively, could get to 100% market penetration over time (meaning, every relevant company has one), in a way that was never true for prior data technologies like traditional data warehouses such as Vertica (too expensive and cumbersome to deploy) and Hadoop (too experimental and technical).
While this doesn’t mean that every data warehouse vendor and every data startup, or even market segment, will be successful, directionally this bodes incredibly well for the data/AI industry as a whole.
The titanic shock: Snowflake vs. Databricks
Snowflake has been the poster child of the data space recently. Its IPO in September 2020 was the biggest software IPO ever (we had covered it at the time in our Quick S-1 Teardown: Snowflake). At the time of writing, and after some ups and downs, it is a $95 billion market cap public company.
However, Databricks is now emerging as a major industry rival. On August 31, the company announced a massive $1.6 billion financing round at a $38 billion valuation, just a few months after a $1 billion round announced in February 2021 (at a measly $28 billion valuation).
Up until recently, Snowflake and Databricks were in fairly different segments of the market (and in fact were close partners for a while).
Snowflake, as a cloud data warehouse, is mostly a database to store and process large amounts of structured data — meaning, data that can fit neatly into rows and columns. Historically, it’s been used to enable companies to answer questions about past and current performance (“which were our top fastest growing regions last quarter?”), by plugging in business intelligence (BI) tools. Like other databases, it leverages SQL, a very popular and accessible query language, which makes it usable by millions of potential users around the world.
Databricks came from a different corner of the data world. It started in 2013 to commercialize Spark, an open source framework to process large volumes of generally unstructured data (any kind of text, audio, video, etc.). Spark users used the framework to build and process what became known as “data lakes,” where they would dump just about any kind of data without worrying about structure or organization. A primary use of data lakes was to train ML/AI applications, enabling companies to answer questions about the future (“which customers are the most likely to purchase next quarter?” — i.e., predictive analytics). To help customers with their data lakes, Databricks created Delta, and to help them with ML/AI, it created ML Flow. For the whole story on that journey, see my Fireside Chat with Ali Ghodsi, CEO, Databricks.
More recently, however, the two companies have converged towards one another.
Databricks started adding data warehousing capabilities to its data lakes, enabling data analysts to run standard SQL queries, as well as adding business intelligence tools like Tableau or Microsoft Power BI. The result is what Databricks calls the lakehouse — a platform meant to combine the best of both data warehouses and data lakes.
As Databricks made its data lakes look more like data warehouses, Snowflake has been making its data warehouses look more like data lakes. It announced support for unstructured data such as audio, video, PDFs, and imaging data in November 2020 and launched it in preview just a few days ago.
And where Databricks has been adding BI to its AI capabilities, Snowflake is adding AI to its BI compatibility. Snowflake has been building close partnerships with top enterprise AI platforms. Snowflake invested in Dataiku, and named it its Data Science Partner of the Year. It also invested in ML platform rival DataRobot.
Ultimately, both Snowflake and Databricks want to be the center of all things data: one repository to store all data, whether structured or unstructured, and run all analytics, whether historical (business intelligence) or predictive (data science, ML/AI).
Of course, there’s no lack of other competitors with a similar vision. The cloud hyperscalers in particular have their own data warehouses, as well as a full suite of analytical tools for BI and AI, and many other capabilities, in addition to massive scale. For example, listen to this great episode of the Data Engineering Podcast about GCP’s data and analytics capabilities.
Both Snowflake and Databricks have had very interesting relationships with cloud vendors, both as friend and foe. Famously, Snowflake grew on the back of AWS (despite AWS’s competitive product, Redshift) for years before expanding to other cloud platforms. Databricks built a strong partnership with Microsoft Azure, and now touts its multi-cloud capabilities to help customers avoid cloud vendor lock-in. For many years, and still to this day to some extent, detractors emphasized that both Snowflake’s and Databricks’ business models effectively resell underlying compute from the cloud vendors, which put their gross margins at the mercy of whatever pricing decisions the hyperscalers would make.
Watching the dance between the cloud providers and the data behemoths will be a defining story of the next five years.
Bundling, unbundling, consolidation?
Given the rise of Snowflake and Databricks, some industry observers are asking if this is the beginning of a long-awaited wave of consolidation in the industry: functional consolidation as large companies bundle an increasing amount of capabilities into their platforms and gradually make smaller startups irrelevant, and/or corporate consolidation, as large companies buy smaller ones or drive them out of business.
Certainly, functional consolidation is happening in the data and AI space, as industry leaders ramp up their ambitions. This is clearly the case for Snowflake and Databricks, and the cloud hyperscalers, as just discussed.
But others have big plans as well. As they grow, companies want to bundle more and more functionality — nobody wants to be a single-product company.
For example, Confluent, a platform for streaming data that just went public in June 2021, wants to go beyond the real-time data use cases it is known for, and “unify the processing of data in motion and data at rest” (see our Quick S-1 Teardown: Confluent).
As another example, Dataiku* natively covers all the functionality otherwise offered by dozens of specialized data and AI infrastructure startups, from data prep to machine learning, DataOps, MLOps, visualization, AI explainability, etc., all bundled in one platform, with a focus on democratization and collaboration (see our Fireside Chat with Florian Douetteau, CEO, Dataiku).
Arguably, the rise of the “modern data stack” is another example of functional consolidation. At its core, it is a de facto alliance among a group of companies (mostly startups) that, as a group, functionally cover all the different stages of the data journey from extraction to the data warehouse to business intelligence — the overall goal being to offer the market a coherent set of solutions that integrate with one another.
For the users of those technologies, this trend towards bundling and convergence is healthy, and many will welcome it with open arms. As it matures, it is time for the data industry to evolve beyond its big technology divides: transactional vs. analytical, batch vs. real-time, BI vs. AI.
These somewhat artificial divides have deep roots, both in the history of the data ecosystem and in technology constraints. Each segment had its own challenges and evolution, resulting in a different tech stack and a different set of vendors. This has led to a lot of complexity for the users of those technologies. Engineers have had to stitch together suites of tools and solutions and maintain complex systems that often end up looking like Rube Goldberg machines.
As they continue to scale, we expect industry leaders to accelerate their bundling efforts and keep pushing messages such as “unified data analytics.” This is good news for Global 2000 companies in particular, which have been the prime target customer for the bigger, bundled data and AI platforms. Those companies have both a tremendous amount to gain from deploying modern data infrastructure and ML/AI, and at the same time much more limited access to top data and ML engineering talent needed to build or assemble data infrastructure in-house (as such talent tends to prefer to work either at Big Tech companies or promising startups, on the whole).
However, as much as Snowflake and Databricks would like to become the single vendor for all things data and AI, we believe that companies will continue to work with multiple vendors, platforms, and tools, in whichever combination best suits their needs.
The key reason: The pace of innovation is just too explosive in the space for things to remain static for too long. Founders launch new startups; Big Tech companies create internal data/AI tools and then open-source them; and for every established technology or product, a new one seems to emerge weekly. Even the data warehouse space, possibly the most established segment of the data ecosystem currently, has new entrants like Firebolt, promising vastly superior performance.
While the big bundled platforms have Global 2000 enterprises as core customer base, there is a whole ecosystem of tech companies, both startups and Big Tech, that are avid consumers of all the new tools and technologies, giving the startups behind them a great initial market. Those companies do have access to the right data and ML engineering talent, and they are willing and able to do the stitching of best-of-breed new tools to deliver the most customized solutions.
Meanwhile, just as the big data warehouse and data lake vendors are pushing their customers towards centralizing all things on top of their platforms, new frameworks such as the data mesh emerge, which advocate for a decentralized approach, where different teams are responsible for their own data product. While there are many nuances, one implication is to evolve away from a world where companies just move all their data to one big central repository. Should it take hold, the data mesh could have a significant impact on architectures and the overall vendor landscape (more on the data mesh later in this post).
Beyond functional consolidation, it is also unclear how much corporate consolidation (M&A) will happen in the near future.
We’re likely to see a few very large, multi-billion dollar acquisitions as big players are eager to make big bets in this fast-growing market to continue building their bundled platforms. However, the high valuations of tech companies in the current market will probably continue to deter many potential acquirers. For example, everybody’s favorite industry rumor has been that Microsoft would want to acquire Databricks. However, because the company could fetch a $100 billion or more valuation in public markets, even Microsoft may not be able to afford it.
There is also a voracious appetite for buying smaller startups throughout the market, particularly as later-stage startups keep raising and have plenty of cash on hand. However, there is also voracious interest from venture capitalists to continue financing those smaller startups. It is rare for promising data and AI startups these days to not be able to raise the next round of financing. As a result, comparatively few M&A deals get done these days, as many founders and their VCs want to keep turning the next card, as opposed to joining forces with other companies, and have the financial resources to do so.
Let’s dive further into financing and exit trends.
Financings, IPOs, M&A: A crazy market
As anyone who follows the startup market knows, it’s been crazy out there.
Venture capital has been deployed at an unprecedented pace, surging 157% year-on-year globally to $156 billion in Q2 2021 according to CB Insights. Ever higher valuations led to the creation of 136 newly minted unicorns just in the first half of 2021, and the IPO window has been wide open, with public financings (IPOs, DLs, SPACs) up +687% (496 vs. 63) in the January 1 to June 1 2021 period vs the same period in 2020.
In this general context of market momentum, data and ML/AI have been hot investment categories once again this past year.
Public markets
Not so long ago, there were hardly any “pure play” data / AI companies listed in public markets.
However, the list is growing quickly after a strong year for IPOs in the data / AI world. We started a public market index to help track the performance of this growing category of public companies — see our MAD Public Company Index (update coming soon).
On the IPO front, particularly noteworthy were UiPath, an RPA and AI automation company, and Confluent, a data infrastructure company focused on real-time streaming data (see our Confluent S-1 teardown for our analysis). Other notable IPOs were C3.ai, an AI platform (see our C3 S-1 teardown), and Couchbase, a no-SQL database.
Several vertical AI companies also had noteworthy IPOs: SentinelOne, an autonomous AI endpoint security platform; TuSimple, a self-driving truck developer; Zymergen, a biomanufacturing company; Recursion, an AI-driven drug discovery company; and Darktrace, “a world-leading AI for cyber-security” company.
Meanwhile, existing public data/AI companies have continued to perform strongly.
While they’re both off their all-time highs, Snowflake is a formidable $95 billion market cap company, and, for all the controversy, Palantir is a $55 billion market cap company, at the time of writing.
Both Datadog and MongoDB are at their all-time highs. Datadog is now a $45 billion market cap company (an important lesson for investors). MongoDB is a $33 billion company, propelled by the rapid growth of its cloud product, Atlas.
Overall, as a group, data and ML/AI companies have vastly outperformed the broader market. And they continue to command high premiums — out of the top 10 companies with the highest market capitalization to revenue multiple, 4 of them (including the top 2) are data/AI companies.
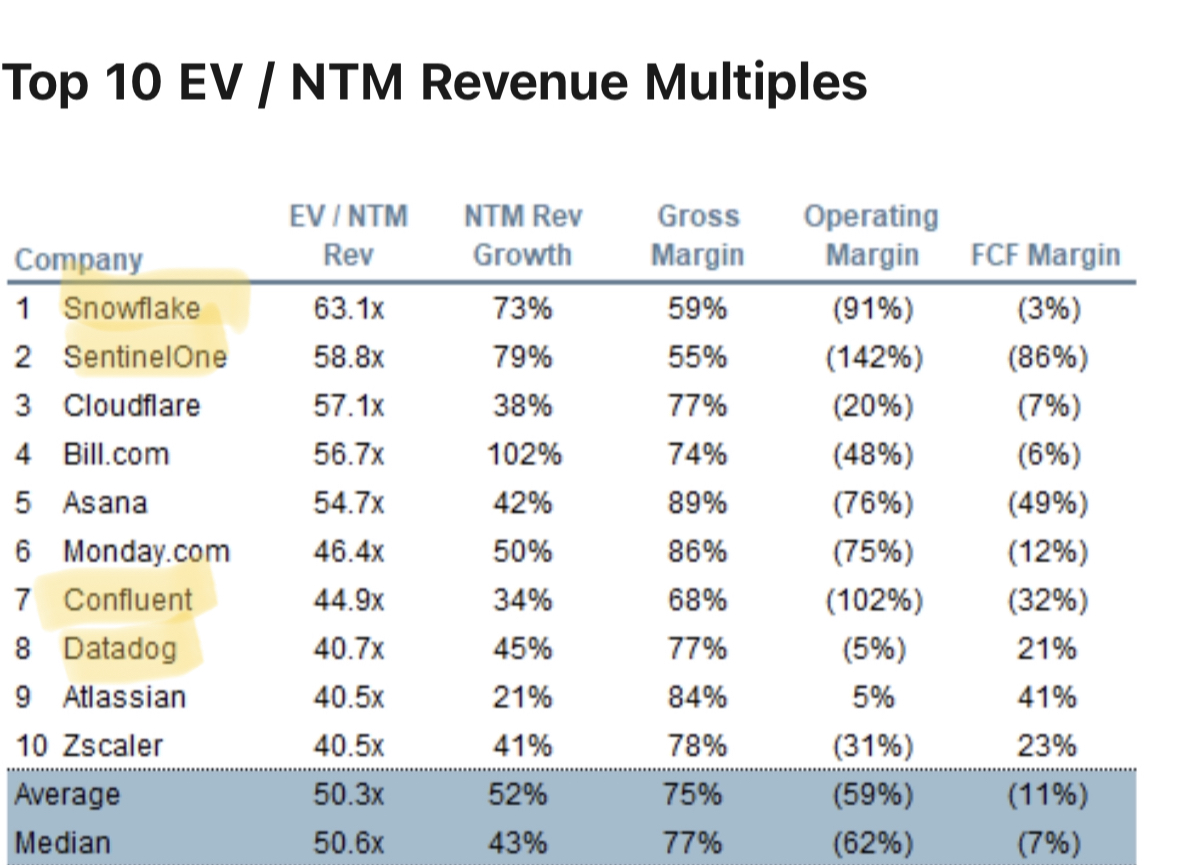
Above: Source: Jamin Ball, Clouded Judgement, September 24, 2021
Private markets
The frothiness of the venture capital market is a topic for another blog post (just a consequence of macroeconomics and low-interest rates, or a reflection of the fact that we have truly entered the deployment phase of the internet?). But suffice to say that, in the context of an overall booming VC market, investors have shown tremendous enthusiasm for data/AI startups.
According to CB Insights, in the first half of 2021, investors had poured $38 billion into AI startups, surpassing the full 2020 amount of $36 billion with half a year to go. This was driven by 50+ mega-sized $100 million-plus rounds, also a new high. Forty-two AI companies reached unicorn valuations in the first half of the year, compared to only 11 for the entirety of 2020.
One inescapable feature of the 2020-2021 VC market has been the rise of crossover funds, such as Tiger Global, Coatue, Altimeter, Dragoneer, or D1, and other mega-funds such as Softbank or Insight. While those funds have been active across the Internet and software landscape, data and ML/AI has clearly been a key investing theme.
As an example, Tiger Global seems to love data/AI companies. Just in the last 12 months, the New York hedge fund has written big checks into many of the companies appearing on our landscape, including, for example, Deep Vision, Databricks, Dataiku*, DataRobot, Imply, Prefect, Gong, PathAI, Ada*, Vast Data, Scale AI, Redis Labs, 6sense, TigerGraph, UiPath, Cockroach Labs*, Hyperscience*, and a number of others.
This exceptional funding environment has mostly been great news for founders. Many data/AI companies found themselves the object of preemptive rounds and bidding wars, giving full power to founders to control their fundraising processes. As VC firms competed to invest, round sizes and valuations escalated dramatically. Series A round sizes used to be in the $8-$12 million range just a few years ago. They are now routinely in the $15-$20 million range. Series A valuations that used to be in the $25-$45 million (pre-money) range now often reach $80-$120 million — valuations that would have been considered a great series B valuation just a few years ago.
On the flip side, the flood of capital has led to an ever-tighter job market, with fierce competition for data, machine learning, and AI talent among many well-funded startups, and corresponding compensation inflation.
Another downside: As VCs aggressively invested in emerging sectors up and down the data stack, often betting on future growth over existing commercial traction, some categories went from nascent to crowded very rapidly — reverse ETL, data quality, data catalogs, data annotation, and MLOps.
Regardless, since our last landscape, an unprecedented number of data/AI companies became unicorns, and those that were already unicorns became even more highly valued, with a couple of decacorns (Databricks, Celonis).
Some noteworthy unicorn-type financings (in rough reverse chronological order): Fivetran, an ETL company, raised $565 million at a $5.6 billion valuation; Matillion, a data integration company, raised $150 million at a $1.5 billion valuation; Neo4j, a graph database provider, raised $325 million at a more than $2 billion valuation; Databricks, a provider of data lakehouses, raised $1.6 billion at a $38 billion valuation; Dataiku*, a collaborative enterprise AI platform, raised $400 million at a $4.6 billion valuation; DBT Labs (fka Fishtown Analytics), a provider of open-source analytics engineering tool, raised a $150 million series C; DataRobot, an enterprise AI platform, raised $300 million at a $6 billion valuation; Celonis, a process mining company, raised a $1 billion series D at an $11 billion valuation; Anduril, an AI-heavy defense technology company, raised a $450 million round at a $4.6 billion valuation; Gong, an AI platform for sales team analytics and coaching, raised $250 million at a $7.25 billion valuation; Alation, a data discovery and governance company, raised a $110 million series D at a $1.2 billion valuation; Ada*, an AI chatbot company, raised a $130 million series C at a $1.2 billion valuation; Signifyd, an AI-based fraud protection software company, raised $205 million at a $1.34 billion valuation; Redis Labs, a real-time data platform, raised a $310 million series G at a $2 billion valuation; Sift, an AI-first fraud prevention company, raised $50 million at a valuation of over $1 billion; Tractable, an AI-first insurance company, raised $60 million at a $1 billion valuation; SambaNova Systems, a specialized AI semiconductor and computing platform, raised $676 million at a $5 billion valuation; Scale AI, a data annotation company, raised $325 million at a $7 billion valuation; Vectra, a cybersecurity AI company, raised $130 million at a $1.2 billion valuation; Shift Technology, an AI-first software company built for insurers, raised $220 million; Dataminr, a real-time AI risk detection platform, raised $475 million; Feedzai, a fraud detection company, raised a $200 million round at a valuation of over $1 billion; Cockroach Labs*, a cloud-native SQL database provider, raised $160 million at a $2 billion valuation; Starburst Data, an SQL-based data query engine, raised a $100 million round at a $1.2 billion valuation; K Health, an AI-first mobile virtual healthcare provider, raised $132 million at a $1.5 billion valuation; Graphcore, an AI chipmaker, raised $222 million; and Forter, a fraud detection software company, raised a $125 million round at a $1.3 billion valuation.
Acquisitions
As mentioned above, acquisitions in the MAD space have been robust but haven’t spiked as much as one would have guessed, given the hot market. The unprecedented amount of cash floating in the ecosystem cuts both ways: More companies have strong balance sheets to potentially acquire others, but many potential targets also have access to cash, whether in private/VC markets or in public markets, and are less likely to want to be acquired.
Of course, there have been several very large acquisitions: Nuance, a public speech and text recognition company (with a particular focus on healthcare), is in the process of getting acquired by Microsoft for almost $20 billion (making it Microsoft’s second-largest acquisition ever, after LinkedIn); Blue Yonder, an AI-first supply chain software company for retail, manufacturing, and logistics customers, was acquired by Panasonic for up to $8.5 billion; Segment, a customer data platform, was acquired by Twilio for $3.2 billion; Kustomer, a CRM that enables businesses to effectively manage all customer interactions across channels, was acquired by Facebook for $1 billion; and Turbonomic, an “AI-powered Application Resource Management” company, was acquired by IBM for between $1.5 billion and $2 billion.
There were also a couple of take-private acquisitions of public companies by private equity firms: Cloudera, a formerly high-flying data platform, was acquired by Clayton Dubilier & Rice and KKR, perhaps the official end of the Hadoop era; and Talend, a data integration provider, was taken private by Thoma Bravo.
Some other notable acquisitions of companies that appeared on earlier versions of this MAD landscape: ZoomInfo acquired Chorus.ai and Everstring; DataRobot acquired Algorithmia; Cloudera acquired Cazena; Relativity acquired Text IQ*; Datadog acquired Sqreen and Timber*; SmartEye acquired Affectiva; Facebook acquired Kustomer; ServiceNow acquired Element AI; Vista Equity Partners acquired Gainsight; AVEVA acquired OSIsoft; and American Express acquired Kabbage.
What’s new for the 2021 MAD landscape
Given the explosive pace of innovation, company creation, and funding in 2020-21, particularly in data infrastructure and MLOps, we’ve had to change things around quite a bit in this year’s landscape.
One significant structural change: As we couldn’t fit it all in one category anymore, we broke “Analytics and Machine Intelligence” into two separate categories, “Analytics” and “Machine Learning & Artificial Intelligence.”
We added several new categories:
- In “Infrastructure,” we added:
- “Reverse ETL” — products that funnel data from the data warehouse back into SaaS applications
- “Data Observability” — a rapidly emerging component of DataOps focused on understanding and troubleshooting the root of data quality issues, with data lineage as a core foundation
- “Privacy & Security” — data privacy is increasingly top of mind, and a number of startups have emerged in the category
- In “Analytics,” we added:
- “Data Catalogs & Discovery” — one of the busiest categories of the last 12 months; those are products that enable users (both technical and non-technical) to find and manage the datasets they need
- “Augmented Analytics” — BI tools are taking advantage of NLG / NLP advances to automatically generate insights, particularly democratizing data for less technical audiences
- “Metrics Stores” — a new entrant in the data stack which provides a central standardized place to serve key business metrics
- “Query Engines“
- In “Machine Learning and AI,” we broke down several MLOps categories into more granular subcategories:
- “Model Building“
- “Feature Stores“
- “Deployment and Production“
- In “Open Source,” we added:
- “Format“
- “Orchestration“
- “Data Quality & Observability“
Another significant evolution: In the past, we tended to overwhelmingly feature on the landscape the more established companies — growth-stage startups (Series C or later) as well as public companies. However, given the emergence of the new generation of data/AI companies mentioned earlier, this year we’ve featured a lot more early startups (series A, sometimes seed) than ever before.
Without further ado, here’s the landscape:

Above: Chart from mattturck.com showing 2021’s key trends in data infrastructure.
- VIEW THE CHART IN FULL SIZE and HIGH RESOLUTION: CLICK HERE
- FULL LIST IN SPREADSHEET FORMAT: Despite how busy the landscape is, we cannot possibly fit in every interesting company on the chart itself. As a result, we have a whole spreadsheet that not only lists all the companies in the landscape, but also hundreds more — CLICK HERE
Key trends in data infrastructure
In last year’s landscape, we had identified some of the key data infrastructure trends of 2020:
As a reminder, here are some of the trends we wrote about LAST YEAR (2020):
- The modern data stack goes mainstream
- ETL vs. ELT
- Automation of data engineering?
- Rise of the data analyst
- Data lakes and data warehouses merging?
- Complexity remains
Of course, the 2020 write-up is less than a year old, and those are multi-year trends that are still very much developing and will continue to do so.
Now, here’s our round-up of some key trends for THIS YEAR (2021):
- The data mesh
- A busy year for DataOps
- It’s time for real time
- Metrics stores
- Reverse ETL
- Data sharing
The data mesh
Everyone’s new favorite topic of 2021 is the “data mesh,” and it’s been fun to see it debated on Twitter among the (admittedly pretty small) group of people that obsess about those topics.
The concept was first introduced by Zhamak Dehghani in 2019 (see her original article, “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh“), and it’s gathered a lot of momentum throughout 2020 and 2021.
The data mesh concept is in large part an organizational idea. A standard approach to building data infrastructure and teams so far has been centralization: one big platform, managed by one data team, that serves the needs of business users. This has advantages but also can create a number of issues (bottlenecks, etc.). The general concept of the data mesh is decentralization — create independent data teams that are responsible for their own domain and provide data “as a product” to others within the organization. Conceptually, this is not entirely different from the concept of micro-services that has become familiar in software engineering, but applied to the data domain.
The data mesh has a number of important practical implications that are being actively debated in data circles.
Should it take hold, it would a great tailwind for startups that provide the kind of tools that are mission-critical in a decentralized data stack.
Starburst, a SQL query engine to access and analyze data across repositories, has rebranded itself as “the analytics engine for the data mesh.” It is even sponsoring Dehghani’s new book on the topic.
Technologies like orchestration engines (Airflow, Prefect, Dagster) that help manage complex pipelines would become even more mission-critical. See my Fireside chat with Nick Schrock (Founder & CEO, Elementl), the company behind the orchestration engine Dagster.
Tracking data across repositories and pipelines would become even more essential for troubleshooting purposes, as well as compliance and governance, reinforcing the need for data lineage. The industry is getting ready for this world, with for example OpenLineage, a new cross-industry initiative to standard data lineage collection. See my Fireside Chat with Julien Le Dem, CTO of Datakin*, the company that helped start the OpenLineage initiative.
*** For anyone interested, we will host Zhamak Dehghani at Data Driven NYC on October 14, 2021. It will be a Zoom session, open to everyone! Enter your email address here to get notified about the event. ***
A busy year for DataOps
While the concept of DataOps has been floating around for years (and we mentioned it in previous versions of this landscape), activity has really picked up recently.
As tends to be the case for newer categories, the definition of DataOps is somewhat nebulous. Some view it as the application of DevOps (from the world software of engineering) to the world of data; others view it more broadly as anything that involves building and maintaining data pipelines and ensuring that all data producers and consumers can do what they need to do, whether finding the right dataset (through a data catalog) or deploying a model in production. Regardless, just like DevOps, it is a combination of methodology, processes, people, platforms, and tools.
The broad context is that data engineering tools and practices are still very much behind the level of sophistication and automation of their software engineering cousins.
The rise of DataOps is one of the examples of what we mentioned earlier in the post: As core needs around storage and processing of data are now adequately addressed, and data/AI is becoming increasingly mission-critical in the enterprise, the industry is naturally evolving towards the next levels of the hierarchy of data needs and building better tools and practices to make sure data infrastructure can work and be maintained reliably and at scale.
A whole ecosystem of early-stage DataOps startups that sprung up recently, covering different parts of the category, but with more or less the same ambition of becoming the “Datadog of the data world” (while Datadog is sometimes used for DataOps purposes and may enter the space at one point or another, it has been historically focused on software engineering and operations).
Startups are jockeying to define their sub-category, so a lot of terms are floating around, but here are some of the key concepts.
Data observability is the general concept of using automated monitoring, alerting, and triaging to eliminate “data downtime,” a term coined by Monte Carlo Data, a vendor in the space (alongside others like BigEye and Databand).
Observability has two core pillars. One is data lineage, which is the ability to follow the path of data through pipelines and understand where issues arise, and where data comes from (for compliance purposes). Data lineage has its own set of specialized startups like Datakin* and Manta.
The other pillar is data quality, which has seen a rush of new entrants. Detecting quality issues in data is both essential and a lot thornier than in the world of software engineering, as each dataset is a little different. Different startups have different approaches. One is declarative, meaning that people can explicitly set rules for what is a quality dataset and what is not. This is the approach of Superconductive, the company behind the popular open-source project Great Expectations (see our Fireside Chat with Abe Gong, CEO, Superconductive). Another approach relies more heavily on machine learning to automate the detection of quality issues (while still using some rules) — Anomalo being a startup with such an approach.
A related emerging concept is data reliability engineering (DRE), which echoes the sister discipline of site reliability engineering (SRE) in the world of software infrastructure. DRE are engineers who solve operational/scale/reliability problems for data infrastructure. Expect more tooling (alerting, communication, knowledge sharing, etc.) to appear on the market to serve their needs.
Finally, data access and governance is another part of DataOps (broadly defined) that has experienced a burst of activity. Growth stage startups like Collibra and Alation have been providing catalog capabilities for a few years now — basically an inventory of available data that helps data analysts find the data they need. However, a number of new entrants have joined the market more recently, including Atlan and Stemma, the commercial company behind the open source data catalog Amundsen (which started at Lyft).
It’s time for real time
“Real-time” or “streaming” data is data that is processed and consumed immediately after it’s generated. This is in opposition to “batch,” which has been the dominant paradigm in data infrastructure to date.
One analogy we came up with to explain the difference: Batch is like blocking an hour to go through your inbox and replying to your email; streaming is like texting back and forth with someone.
Real-time data processing has been a hot topic since the early days of the Big Data era, 10-15 years ago — notably, processing speed was a key advantage that precipitated the success of Spark (a micro-batching framework) over Hadoop MapReduce.
However, for years, real-time data streaming was always the market segment that was “about to explode” in a very major way, but never quite did. Some industry observers argued that the number of applications for real-time data is, perhaps counter-intuitively, fairly limited, revolving around a finite number of use cases like online fraud detection, online advertising, Netflix-style content recommendations, or cybersecurity.
The resounding success of the Confluent IPO has proved the naysayers wrong. Confluent is now a $17 billion market cap company at the time of writing, having nearly doubled since its June 24, 2021 IPO. Confluent is the company behind Kafka, an open source data streaming project originally developed at LinkedIn. Over the years, the company evolved into a full-scale data streaming platform that enables customers to access and manage data as continuous, real-time streams (again, our S-1 teardown is here).
Beyond Confluent, the whole real-time data ecosystem has accelerated.
Real-time data analytics, in particular, has seen a lot of activity. Just a few days ago, ClickHouse, a real-time analytics database that was originally an open source project launched by Russian search engine Yandex, announced that it has become a commercial, U.S.-based company funded with $50 million in venture capital. Earlier this year, Imply, another real-time analytics platform based on the Druid open source database project, announced a $70 million round of financing. Materialize is another very interesting company in the space — see our Fireside Chat with Arjun Narayan, CEO, Materialize.
Upstream from data analytics, emerging players help simplify real-time data pipelines. Meroxa focuses on connecting relational databases to data warehouses in real time — see our Fireside Chat with DeVaris Brown, CEO, Meroxa. Estuary* focuses on unifying the real-time and batch paradigms in an effort to abstract away complexity.
Metrics stores
Data and data use increased in both frequency and complexity at companies over the last few years. With that increase in complexity comes an accompanied increase in headaches caused by data inconsistencies. For any specific metric, any slight derivation in the metric, whether caused by dimension, definition, or something else, can cause misaligned outputs. Teams perceived to be working based off of the same metrics could be working off different cuts of data entirely or metric definitions may slightly shift between times when analysis is conducted leading to different results, sowing distrust when inconsistencies arise. Data is only useful if teams can trust that the data is accurate, every time they use it.
This has led to the emergence of the metric store which Benn Stancil, the chief analytics officer at Mode, labeled the missing piece of the modern data stack. Home-grown solutions that seek to centralize where metrics are defined were announced at tech companies including at AirBnB, where Minerva has a vision of “define once, use anywhere,” and at Pinterest. These internal metrics stores serve to standardize the definitions of key business metrics and all of its dimensions, and provide stakeholders with accurate, analysis-ready data sets based on those definitions. By centralizing the definition of metrics, these stores help teams build trust in the data they are using and democratize cross-functional access to metrics, driving data alignment across the company.
The metrics store sits on top of the data warehouse and informs the data sent to all downstream applications where data is consumed, including business intelligence platforms, analytics and data science tools, and operational applications. Teams define key business metrics in the metric store, ensuring that anybody using a specific metric will derive it using consistent definitions. Metrics stores like Minerva also ensure that data is consistent historically, backfilling automatically if business logic is changed. Finally, the metrics store serves the metrics to the data consumer in the standardized, validated formats. The metrics store enables data consumers on different teams to no longer have to build and maintain their own versions of the same metric, and can rely on one single centralized source of truth.
Some interesting startups building metric stores include Transform, Trace*, and Supergrain.
Reverse ETL
It’s certainly been a busy year in the world of ETL/ELT — the products that aim to extract data from a variety of sources (whether databases or SaaS products) and load them into cloud data warehouses. As mentioned, Fivetran became a $5.6 billion company; meanwhile, newer entrants Airbyte (an open source version) raised a $26 million series A and Meltano spun out of GitLab.
However, one key development in the modern data stack over the last year or so has been the emergence of reverse ETL as a category. With the modern data stack, data warehouses have become the single source of truth for all business data which has historically been spread across various application-layer business systems. Reverse ETL tooling sits on the opposite side of the warehouse from typical ETL/ELT tools and enables teams to move data from their data warehouse back into business applications like CRMs, marketing automation systems, or customer support platforms to make use of the consolidated and derived data in their functional business processes. Reverse ETLs have become an integral part of closing the loop in the modern data stack to bring unified data, but come with challenges due to pushing data back into live systems.
With reverse ETLs, functional teams like sales can take advantage of up-to-date data enriched from other business applications like product engagement from tools like Pendo* to understand how a prospect is already engaging or from marketing programming from Marketo to weave a more coherent sales narrative. Reverse ETLs help break down data silos and drive alignment between functions by bringing centralized data from the data warehouse into systems that these functional teams already live in day-to-day.
A number of companies in the reverse ETL space have received funding in the last year, including Census, Rudderstack, Grouparoo, Hightouch, Headsup, and Polytomic.
Data sharing
Another accelerating theme this year has been the rise of data sharing and data collaboration not just within companies, but also across organizations.
Companies may want to share data with their ecosystem of suppliers, partners, and customers for a whole range of reasons, including supply chain visibility, training of machine learning models, or shared go-to-market initiatives.
Cross-organization data sharing has been a key theme for “data cloud” vendors in particular:
- In May 2021, Google launched Analytics Hub, a platform for combining data sets and sharing data and insights, including dashboards and machine learning models, both inside and outside an organization. It also launched Datashare, a product more specifically targeting financial services and based on Analytics Hub.
- On the same day (!) in May 2021, Databricks announced Delta Sharing, an open source protocol for secure data sharing across organizations.
- In June 2021, Snowflake announced the general availability of its data marketplace, as well as additional capabilities for secure data sharing.
There’s also a number of interesting startups in the space:
- Habr, a provider of enterprise data exchanges
- Crossbeam*, a partner ecosystem platform
Enabling cross-organization collaboration is particularly strategic for data cloud providers because it offers the possibility of building an additional moat for their businesses. As competition intensifies and vendors try to beat each other on features and capabilities, a data-sharing platform could help create a network effect. The more companies join, say, the Snowflake Data Cloud and share their data with others, the more it becomes valuable to each new company that joins the network (and the harder it is to leave the network).
Key trends in ML/AI
In last year’s landscape, we had identified some of the key data infrastructure trends of 2020.
As a reminder, here are some of the trends we wrote about LAST YEAR (2020)
- Boom time for data science and machine learning platforms (DSML)
- ML getting deployed and embedded
- The Year of NLP
Now, here’s our round-up of some key trends for THIS YEAR (2021):
- Feature stores
- The rise of ModelOps
- AI content generation
- The continued emergence of a separate Chinese AI stack
Research in artificial intelligence keeps on improving at a rapid pace. Some notable projects released or published in the last year include DeepMind’s Alphafold, which predicts what shapes proteins fold into, along with multiple breakthroughs from OpenAI including GPT-3, DALL-E, and CLIP.
Additionally, startup funding has drastically accelerated across the machine learning stack, giving rise to a large number of point solutions. With the growing landscape, compatibility issues between solutions are likely to emerge as the machine learning stacks become increasingly complicated. Companies will need to make a decision between buying a comprehensive full-stack solution like DataRobot or Dataiku* versus trying to chain together best-in-breed point solutions. Consolidation across adjacent point solutions is also inevitable as the market matures and faster-growing companies hit meaningful scale.
Feature stores
Feature stores have become increasingly common in the operational machine learning stack since the idea was first introduced by Uber in 2017, with multiple companies raising rounds in the past year to build managed feature stores including Tecton, Rasgo, Logical Clocks, and Kaskada.
A feature (sometimes referred to as a variable or attribute) in machine learning is an individual measurable input property or characteristic, which could be represented as a column in a data snippet. Machine learning models could use anywhere from a single feature to upwards of millions.
Historically, feature engineering had been done in a more ad-hoc manner, with increasingly more complicated models and pipelines over time. Engineers and data scientists often spent a lot of time re-extracting features from the raw data. Gaps between production and experimentation environments could also cause unexpected inconsistencies in model performance and behavior. Organizations are also more concerned with governance, reproducibility, and explainability of their machine learning models, and siloed features make that difficult in practice.
Feature stores promote collaboration and help break down silos. They reduce the overhead complexity and standardize and reuse features by providing a single source of truth across both training (offline) and production (online). It acts as a centralized place to store the large volumes of curated features within an organization, runs the data pipelines which transform the raw data into feature values, and provides low latency read access directly via API. This enables faster development and helps teams both avoid work duplication and maintain consistent feature sets across engineers and between training and serving models. Feature stores also produce and surface metadata such as data lineage for features, health monitoring, drift for both features and online data, and more.
The rise of ModelOps
By this point, most companies recognize that taking models from experimentation to production is challenging, and models in use require constant monitoring and retraining as data shifts. According to IDC, 28% of all ML/AI projects have failed, and Gartner notes that 87% of data science projects never make it into production. Machine Learning Operations (MLOps), which we wrote about in 2019, came about over the next few years as companies sought to close those gaps by applying DevOps best practices. MLOps seeks to streamline the rapid continuous development and deployment of models at scale, and according to Gartner, has hit a peak in the hype cycle.
The new hot concept in AI operations is in ModelOps, a superset of MLOps which aims to operationalize all AI models including ML at a faster pace across every phase of the lifecycle from training to production. ModelOps covers both tools and processes, requiring a cross-functional cultural commitment uniting processes, standardizing model orchestration end-to-end, creating a centralized repository for all models along with comprehensive governance capabilities (tackling lineage, monitoring, etc.), and implementing better governance, monitoring, and audit trails for all models in use.
In practice, well-implemented ModelOps helps increase explainability and compliance while reducing risk for all models by providing a unified system to deploy, monitor, and govern all models. Teams can better make apples-to-apples comparisons between models given standardized processes during training and deployment, release models with faster cycles, be alerted automatically when model performance benchmarks drop below acceptable thresholds, and understand the history and lineage of models in use across the organization.
AI content generation
AI has matured greatly over the last few years and is now being leveraged in creating content across all sorts of mediums, including text, images, code, and videos. Last June, OpenAI released its first commercial beta product — a developer-focused API that contained GPT-3, a powerful general-purpose language model with 175 billion parameters. As of earlier this year, tens of thousands of developers had built more than 300 applications on the platform, generating 4.5 billion words per day on average.
OpenAI has already signed a number of early commercial deals, most notably with Microsoft, which has leveraged GPT-3 within Power Apps to return formulas based on semantic searches, enabling “citizen developers” to generate code with limited coding ability. Additionally, GitHub leveraged OpenAI Codex, a descendant of GPT-3 containing both natural language and billions of lines of source code from public code repositories, to launch the controversial GitHub Copilot, which aims to make coding faster by suggesting entire functions to autocomplete code within the code editor.
With OpenAI primarily focused on English-centric models, a growing number of companies are working on non-English models. In Europe, the German startup Aleph Alpha raised $27 million earlier this year to build a “sovereign EU-based compute infrastructure,” and has built a multilingual language model that can return coherent text results in German, French, Spanish, and Italian in addition to English. Other companies working on language-specific models include AI21 Labs building Jurassic-1 in English and Hebrew, Huawei’s PanGu-α and the Beijing Academy of Artificial Intelligence’s Wudao in Chinese, and Naver’s HyperCLOVA in Korean.
On the image side, OpenAI introduced its 12-billion parameter model called DALL-E this past January, which was trained to create plausible images from text descriptions. DALL-E offers some level of control over multiple objects, their attributes, their spatial relationships, and even perspective and context.
Additionally, synthetic media has matured significantly since the tongue-in-cheek 2018 Buzzfeed and Jordan Peele deepfake Obama. Consumer companies have started to leverage synthetically generated media for everything from marketing campaigns to entertainment. Earlier this year, Synthesia* partnered with Lay’s and Lionel Messi to create Messi Messages, a platform that enabled users to generate video clips of Messi customized with the names of their friends. Some other notable examples within the last year include using AI to de-age Mark Hamill both in appearance and voice in The Mandalorian, have Anthony Bourdain narrate dialogue he never said in Roadrunner, create a State Farm commercial that promoted The Last Dance, and create a synthetic voice for Val Kilmer, who lost his voice during treatment for throat cancer.
With this technological advancement comes an ethical and moral quandary. Synthetic media potentially poses a risk to society including by creating content with bad intentions, such as using hate speech or other image-damaging language, states creating false narratives with synthetic actors, or celebrity and revenge deepfake pornography. Some companies have taken steps to limit access to their technology with codes of ethics like Synthesia* and Sonantic. The debate about guardrails, such as labeling the content as synthetic and identifying its creator and owner, is just getting started, and likely will remain unresolved far into the future.
The continued emergence of a separate Chinese AI stack
China has continued to develop as a global AI powerhouse, with a huge market that is the world’s largest producer of data. The last year saw the first real proliferation of Chinese AI consumer technology with the cross-border Western success of TikTok, based on one of the arguably best AI recommendation algorithms ever created.
With the Chinese government mandating in 2017 for AI supremacy by 2030 and with financial support in the form of billions of dollars of funding supporting AI research along with the establishment of 50 new AI institutions in 2020, the pace of progress has been quick. Interestingly, while much of China’s technology infrastructure still relies on western-created tooling (e.g., Oracle for ERP, Salesforce for CRM), a separate homegrown stack has begun to emerge.
Chinese engineers who use western infrastructure face cultural and language barriers which make it difficult to contribute to western open source projects. Additionally, on the financial side, according to Bloomberg, Chinese-based investors in U.S. AI companies from 2000 to 2020 represent just 2.4% of total AI investment in the U.S. Huawei and ZTE’s spat with the U.S. government hastened the separation of the two infrastructure stacks, which already faced unification headwinds.
With nationalist sentiment at a high, localization (国产化替代) to replace western technology with homegrown infrastructure has picked up steam. The Xinchuang industry (信创) is spearheaded by a wave of companies seeking to build localized infrastructure, from the chip level through the application layer. While Xinchuang has been associated with lower quality and functionality tech, in the past year, clear progress was made within Xinchuang cloud (信创云), with notable launches including Huayun (华云), China Electronics Cloud’s CECstack, and Easystack (易捷行云).
In the infrastructure layer, local Chinese infrastructure players are starting to make headway into major enterprises and government-run organizations. ByteDance launched Volcano Engine targeted toward third parties in China, based on infrastructure developed for its consumer products offering capabilities including content recommendation and personalization, growth-focused tooling like A/B testing and performance monitoring, translation, and security, in addition to traditional cloud hosting solutions. Inspur Group serves 56% of domestic state-owned enterprises and 31% of China’s top 500 companies, while Wuhan Dameng is widely used across multiple sectors. Other examples of homegrown infrastructure include PolarDB from Alibaba, GaussDB from Huawei, TBase from Tencent, TiDB from PingCAP, Boray Data, and TDengine from Taos Data.
On the research side, in April, Huawei introduced the aforementioned PanGu-α, a 200 billion parameter pre-trained language model trained on 1.1TB of a Chinese text from a variety of domains. This was quickly overshadowed when the Beijing Academy of Artificial Intelligence (BAAI) announced the release of Wu Dao 2.0 in June. Wu Dao 2.0 is a multimodal AI that has 1.75 trillion parameters, 10X the number as GPT-3, making it the largest AI language system to date. Its capabilities include handling NLP and image recognition, in addition to generating written media in traditional Chinese, predicting 3D structures of proteins like AlphaFold, and more. Model training was also handled via Chinese-developed infrastructure: In order to train Wu Dao quickly (version 1.0 was only released in March), BAAI researchers built FastMoE, a distributed Mixture-of Experts training system based on PyTorch that doesn’t require Google’s TPU and can run on off-the-shelf hardware.
Watch our fireside chat with Chip Huyen for further discussion on the state of Chinese AI and infrastructure.
[Note: A version of this story originally ran on the author’s own website.]
Matt Turck is a VC at FirstMark, where he focuses on SaaS, cloud, data, ML/AI, and infrastructure investments. Matt also organizes Data Driven NYC, the largest data community in the U.S.
This story originally appeared on Mattturck.com. Copyright 2021
VentureBeat
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact. Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:- up-to-date information on the subjects of interest to you
- our newsletters
- gated thought-leader content and discounted access to our prized events, such as Transform 2021: Learn More
- networking features, and more
"machine" - Google News
October 16, 2021 at 10:40PM
https://ift.tt/3DJrKQP
The 2021 machine learning, AI, and data landscape - VentureBeat
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "The 2021 machine learning, AI, and data landscape - VentureBeat"
Post a Comment