Amazon Web Services claims to have the broadest and most complete set of machine learning capabilities. I honestly don’t know how the company can claim those superlatives with a straight face: Yes, the AWS machine learning offerings are broad and fairly complete and rather impressive, but so are those of Google Cloud and Microsoft Azure.
Amazon SageMaker Clarify is the new add-on to the Amazon SageMaker machine learning ecosystem for Responsible AI. SageMaker Clarify integrates with SageMaker at three points: in the new Data Wrangler to detect data biases at import time, such as imbalanced classes in the training set, in the Experiments tab of SageMaker Studio to detect biases in the model after training and to explain the importance of features, and in the SageMaker Model Monitor, to detect bias shifts in a deployed model over time.
Historically, AWS has presented its services as cloud-only. That is starting to change, at least for big enterprises that can afford to buy racks of proprietary appliances such as AWS Outposts. It’s also changing in AWS’s industrial offerings, such as Amazon Monitron and AWS Panorama, which include some edge devices.
 IDG
IDG
This diagram summarizes the AWS Machine Learning stack as of December 2020. It appeared often during talks at AWS re:Invent.
AWS Machine Learning Services
When I reviewed Amazon SageMaker in 2018, I thought it was quite good and that it had “significantly improved the utility of AWS for data scientists.” Little did I know then how much traction it would get and how much it would expand in scope.
When I looked at SageMaker again in April 2020, it was in a preview phase with seven major improvements and expansions, and I said that it was “good enough to use for end-to-end machine learning and deep learning: data preparation, model training, model deployment, and model monitoring.” I also said that the user experience still needed a little work.
There are now twelve parts in Amazon SageMaker: Studio, Autopilot, Ground Truth, JumpStart, Data Wrangler, Feature Store, Clarify, Debugger, Model Monitor, Distributed Training, Pipelines, and Edge Manager. Several of the new SageMaker features, such as Data Wrangler, are major improvements.
Amazon SageMaker Studio
Amazon SageMaker Studio is an integrated machine learning environment where you can build, train, deploy, and analyze your models all in the same application. The IDE is based on JupiterLab, and now supports both Python and R natively in notebook kernels. It has specific support for seven frameworks: Apache MXNet, Apache Spark, Chainer, PyTorch, Scikit-learn, SparkML Serving, and TensorFlow.
SageMaker Studio seems to be a wrapper around SageMaker Notebooks with a few additional features, including SageMaker JumpStart and a different launcher. Both take you to JupyterLab notebooks for actual calculations.
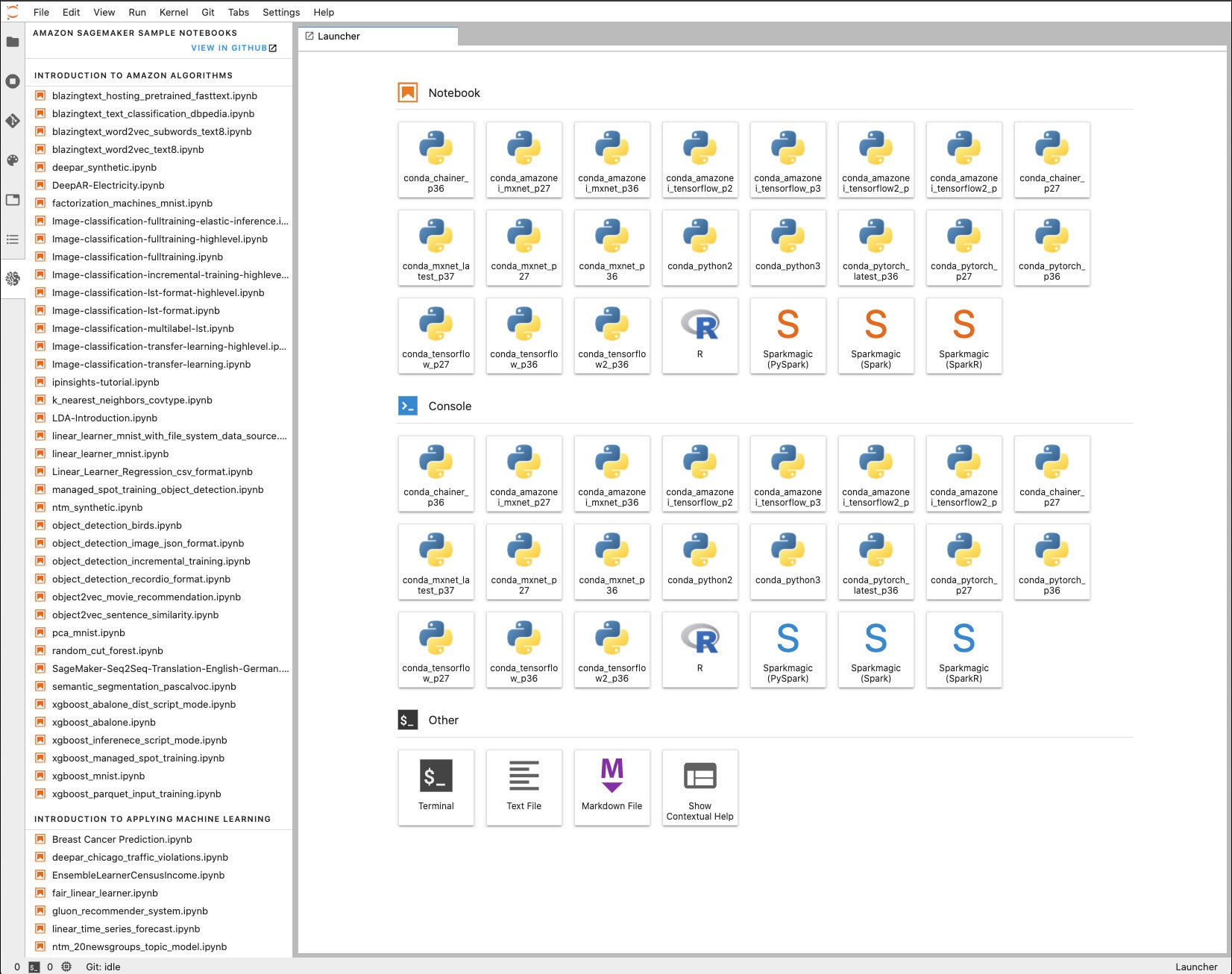
I showed lots of notebook examples in my April 2020 review, but only for Python notebooks. Since then, there are more samples in the repository. Plus, the sample repository is easier to reach from a notebook, and there is now support for R kernels in the notebooks, as shown in the screenshot below. Unlike Microsoft Azure Machine Learning notebooks, SageMaker does not support RStudio.
 IDG
IDG
Amazon SageMaker now supports R kernels as well as Python kernels in its notebooks. This example is a simple “Hello, World” that does some pre-analysis of an abalone measurement dataset. I also tried an end-to-end R sample.
 IDG
IDG
Amazon SageMaker Notebook samples and launcher.
 IDG
IDG
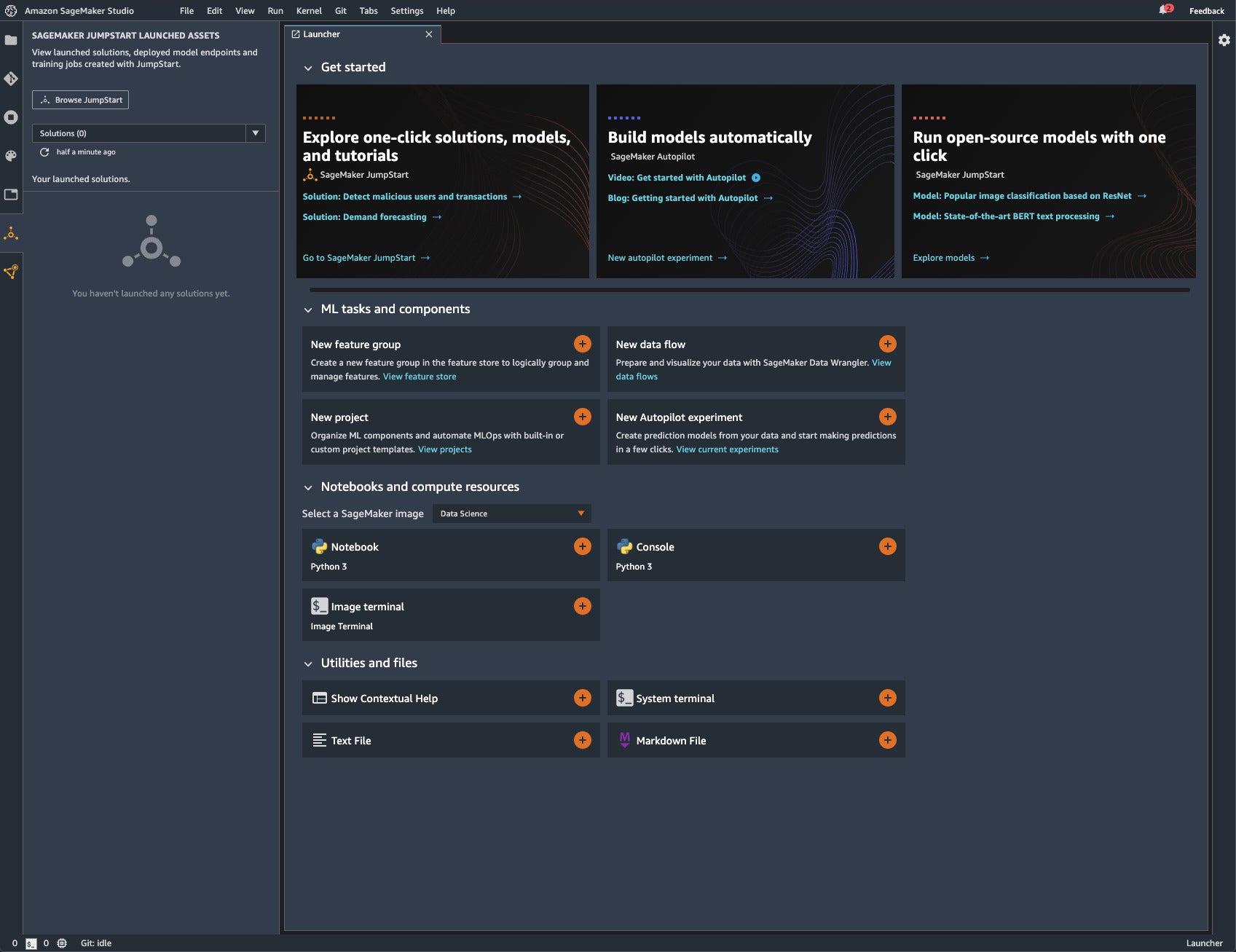
Amazon SageMaker Studio with JumpStart launched assets and Get Started.
Amazon SageMaker Autopilot
In the April review I showed a SageMaker Autopilot sample, which took four hours to run. Looking at another Autopilot sample in the repository, for customer churn prediction, I see that it has been improved by adding a model explainability section. This is a welcome addition, as explainability is one facet of Responsible AI, although not the whole story. (See Amazon SageMaker Clarify, below.)
According to the notes in the sample, the enabling improvement for this in the SageMaker Python SDK, introduced in June 2020, was to allow Autopilot-generated models to be configured to return probabilities of each inference. Unfortunately, that means you need to retrain any Autopilot models produced on previous versions of the SDK if you want to add explainability to them.
Amazon SageMaker Ground Truth
As I discussed in April 2020, SageMaker Ground Truth is a semi-supervised learning process for data labeling that combines human annotations with automatic annotations. I don’t see any notable changes in the service since then.
Amazon SageMaker JumpStart
SageMaker JumpStart is a new “Getting Started” feature of SageMaker Studio, which should help newcomers to SageMaker. As you can see in the screenshot below, there are two new colored icons at the bottom of the left sidebar: the upper one brings up a list of solutions, model endpoints, or training jobs created with SageMaker JumpStart, and the lower one, SageMaker Components and Registries, brings up a list of projects, data wrangler flows, pipelines, experiments, trials, models, or endpoints, or access to the feature store.
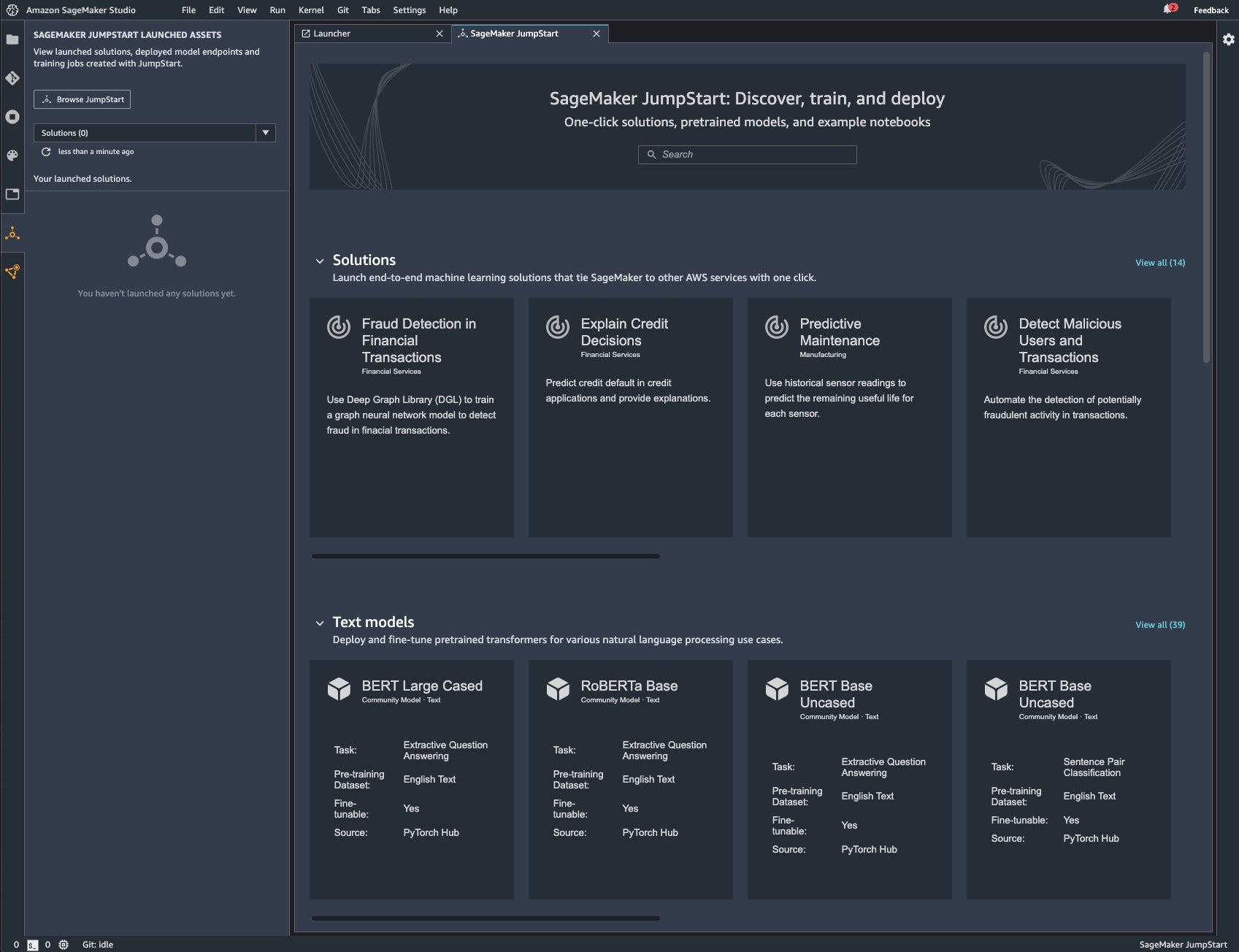
The Browse JumpStart button in the SageMaker JumpStart Launched Assets panel brings up the browser tab at the right. The browser lets you look through end-to-end solutions tied to other AWS services, text models, vision models, built-in SageMaker algorithms, example notebooks, blogs, and video tutorials.
When you click on a solution square in the browser, you bring up a documentation screen for the solution, which includes a button to launch the actual solution. When you click on a model square that has a fine-tuning option, you should see both Deploy and Train buttons on the documentation screen for the model, when I brought up the BERT Large Cased text model the Train button was disabled, and had a note that said “Unfortunately, fine-tuning is not yet available for this model.”
 IDG
IDG
Amazon SageMaker Studio with the SageMaker JumpStart browser.
Amazon SageMaker Data Wrangler
Amazon claims that the new SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning from weeks to minutes. It essentially gives you an interactive workspace where you can import data and try data transformations; on export you can generate a processing notebook.
Supported data transformations include joining and concatenating datasets; custom transforms and formulas; encoding categorical variables; featurizing text and date/time variables; formatting strings; handling outliers and missing values; managing rows, columns, and vectors; processing numeric variables; search and edit; parse value as type; and validate strings. Custom transformations support PySpark, Pandas, and PySpark (SQL) directly, and other Python libraries with import statements.
I’m not sure I buy the “weeks to minutes” claim, unless you already know what you’re doing and could write the code snippets yourself off the top of your head. I’d believe that most people could handle data preparation with SageMaker Data Wrangler in a few hours, given some knowledge of Pandas, PySpark, and machine learning data basics, as well as a feel for statistics.
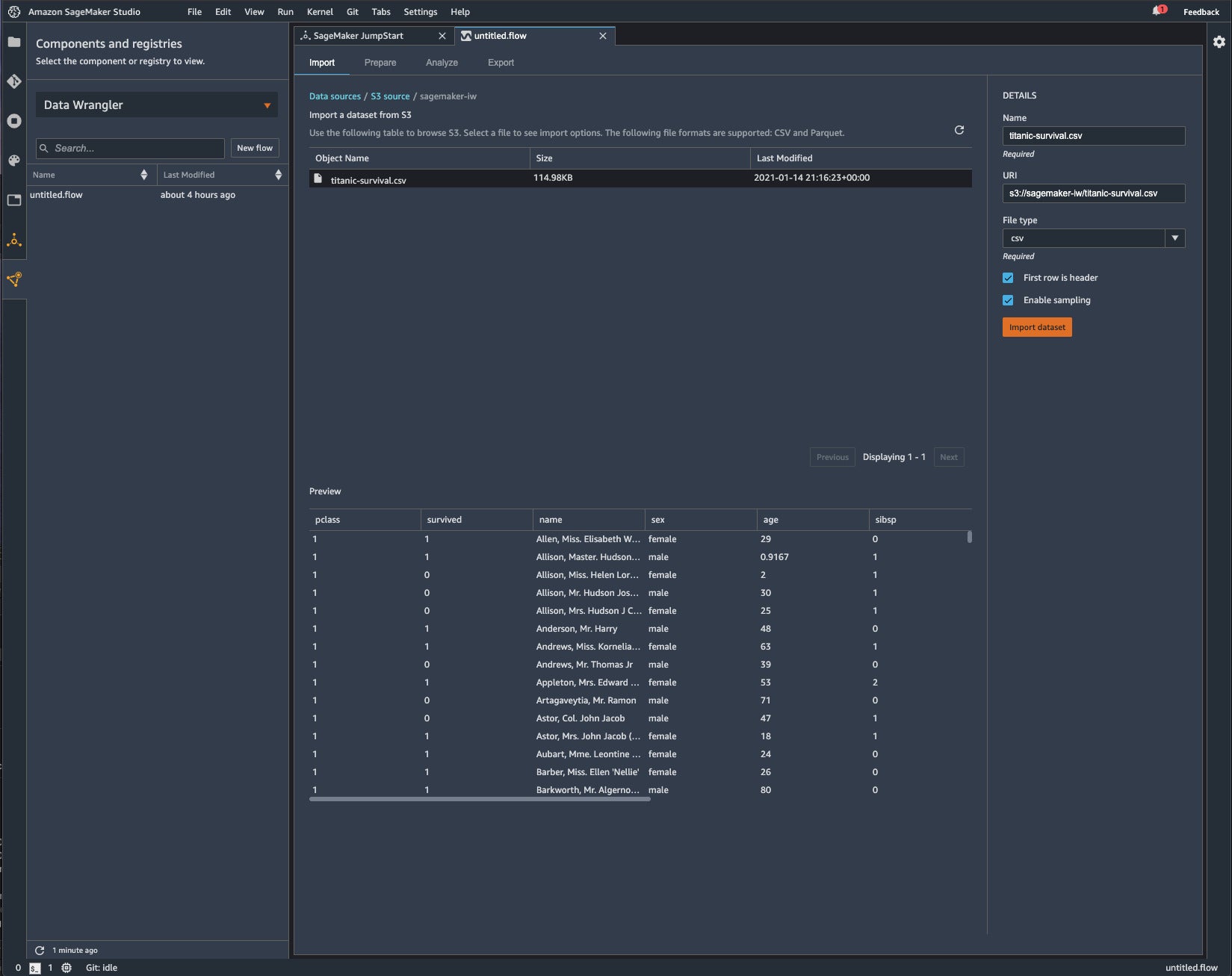
I went through a demo of SageMaker Data Wrangler using a Titanic passenger survival dataset. It took me most of an afternoon, but cost under $2 despite using some sizable VMs for processing.
 IDG
IDG
You can import data into SageMaker Data Wrangler from Amazon S3 buckets, either directly or using Athena (an implementation of Presto SQL). The interface says it supports data uploads directly, but I couldn’t get that to work.
 IDG
IDG
Here I’m using a custom transformation with Pandas code to drop unnecessary columns. Each transformation creates a new DataFrame.
 IDG
IDG
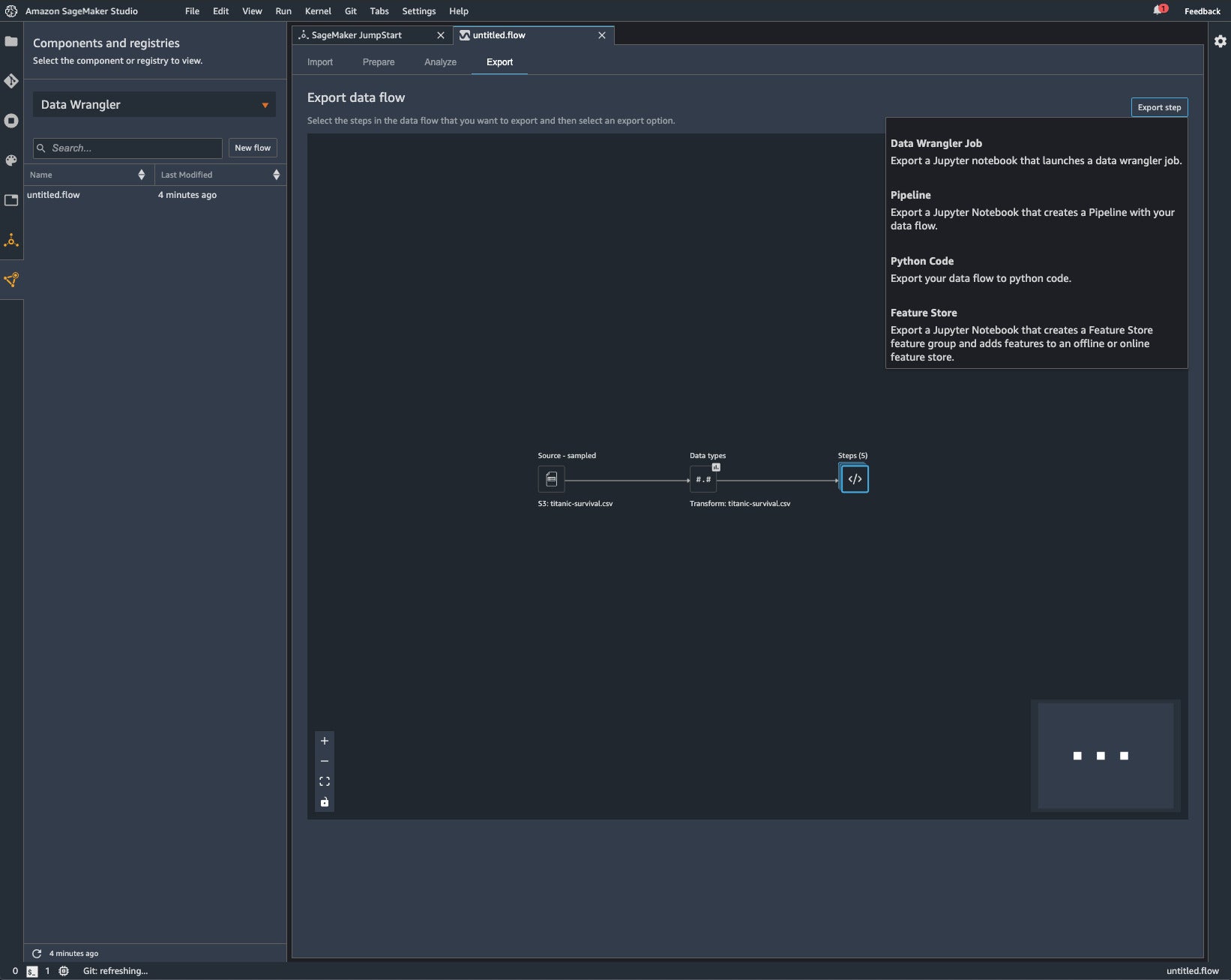
Data imports and preparation steps appear on a data flow diagram. When you export the data flow, you can create a data wrangler job as a Jupyter Notebook, a notebook that creates a Pipeline, a Python code file, or a notebook that creates a Feature Store feature group.
 IDG
IDG
This SageMaker Data Wrangler Job Notebook is the result of an export of a Data Wrangler flow. You can see how the export created a lot of Python code for you that would have been time-consuming to write from scratch.
 IDG
IDG
At the end of the Data Wrangler Job Notebook there’s an optional SageMaker training step using XGBoost. I ran it and saw reasonably good results. Note the instances, apps, and sessions listed at the left.
Amazon SageMaker Feature Store
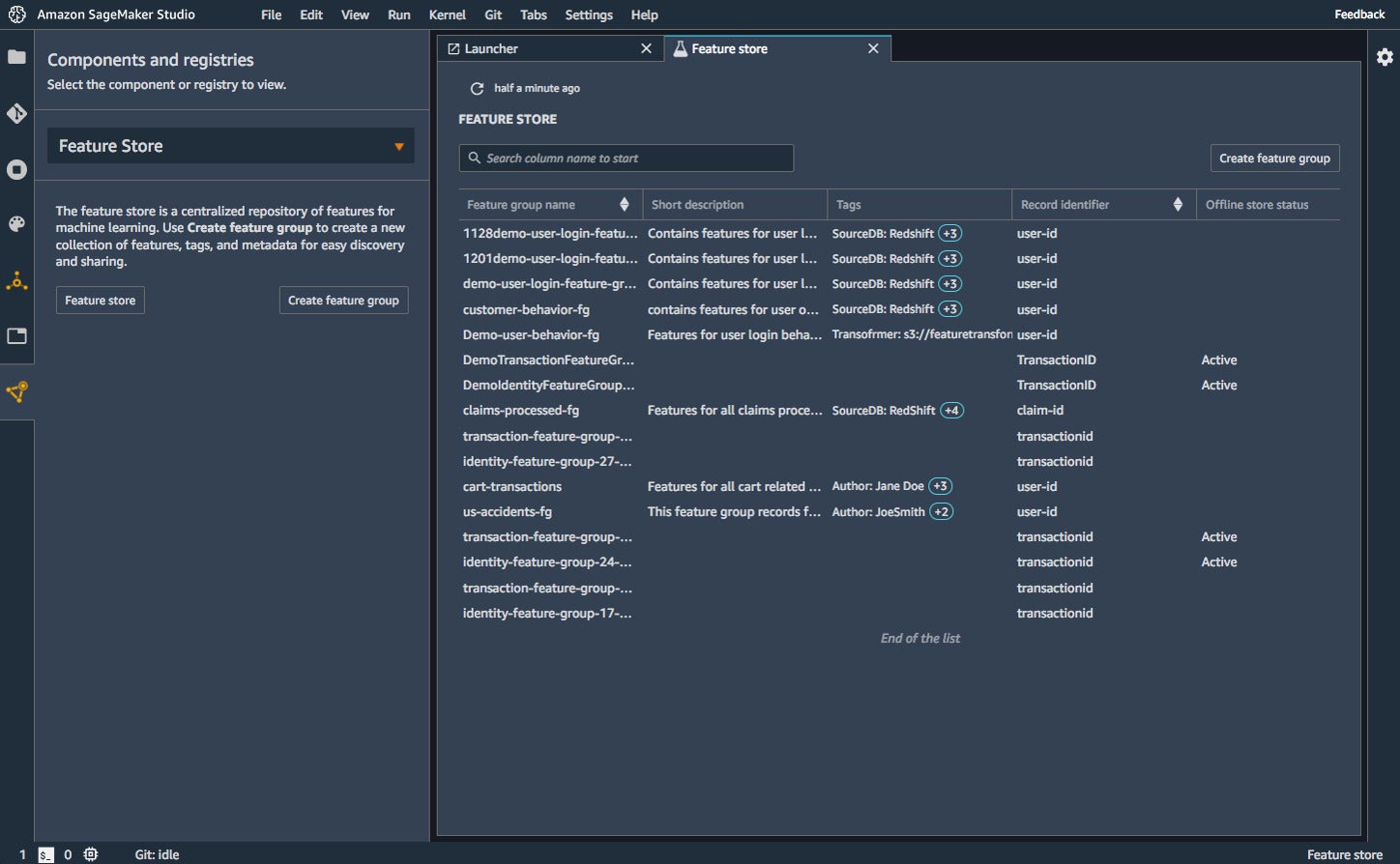
Metadata and data sharing are two of the missing links in most machine learning data. SageMaker Feature Store allows you to fix that: It is a fully managed, purpose-built repository to store, update, retrieve, and share machine learning features. As mentioned in the previous section, one way to generate a feature group in Feature Store is to save the output from a SageMaker Data Wrangler flow. Another way is to use a streaming data source such as Amazon Kinesis Data Firehose. Feature Store allows you to standardize your features (for example by converting them all to the same units of measure) and to use them consistently (for example by using the same data for training and inference).
 IDG
IDG
Amazon SageMaker Feature Store makes it easy to find and reuse features for machine learning.
Amazon SageMaker Clarify
SageMaker Clarify is Amazon’s Responsible AI offering. It integrates with SageMaker at three points: in SageMaker Data Wrangler to detect data biases, such as imbalanced classes in the training set; in the Experiments tab of SageMaker Studio to detect biases in the model and to explain the importance of features; and in the SageMaker Model Monitor, to detect bias shifts over time.
 IDG
IDG
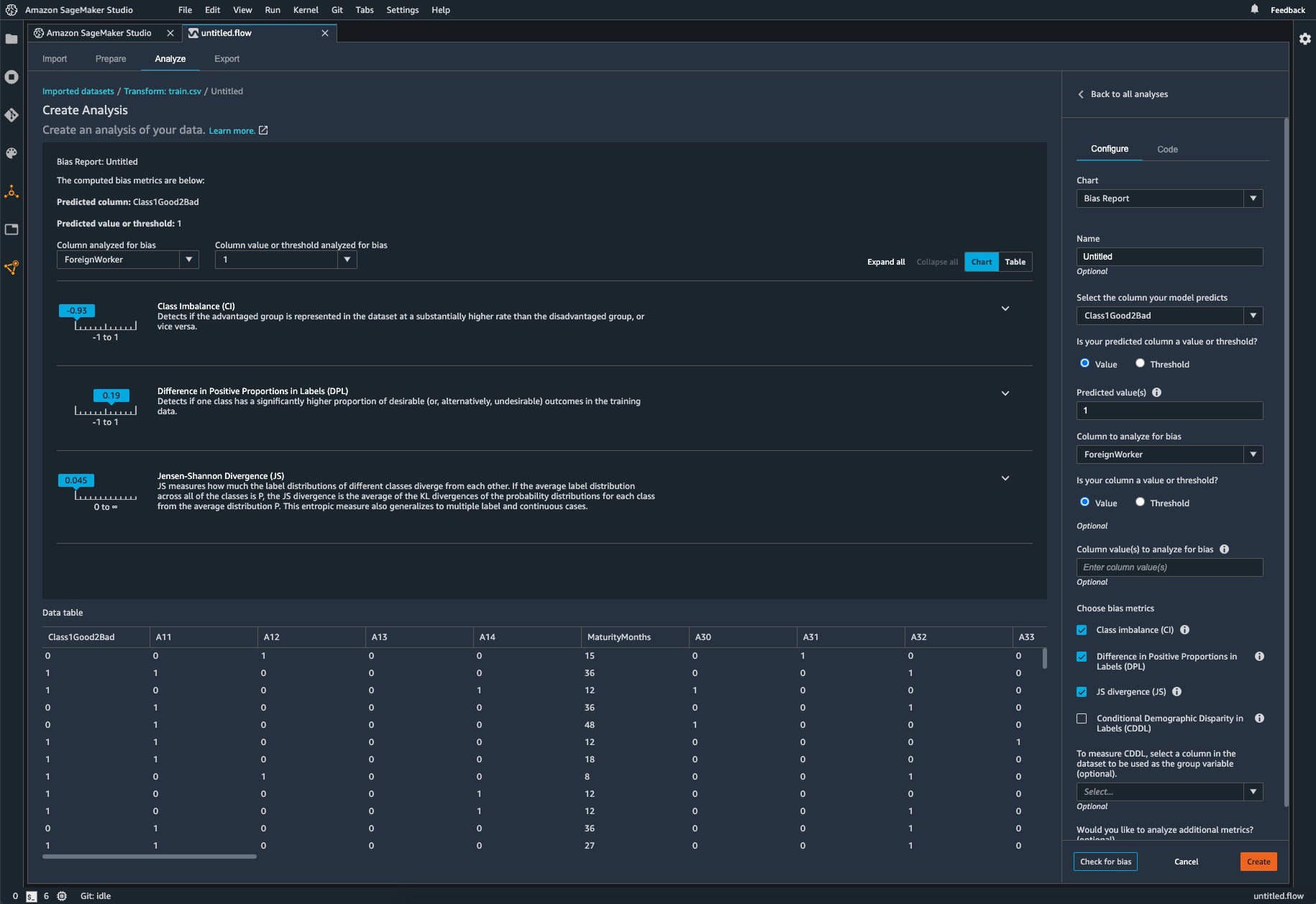
The Analyze step of SageMaker Data Wrangler includes a data bias report, which includes four standard tests: class imbalance (an issue in this dataset); difference in positive proportions in labels; Jensen-Shannon divergence; and conditional demographic disparity in labels, which isn’t checked for this particular report. There are four more tests, classified as “additional.”
 IDG
IDG
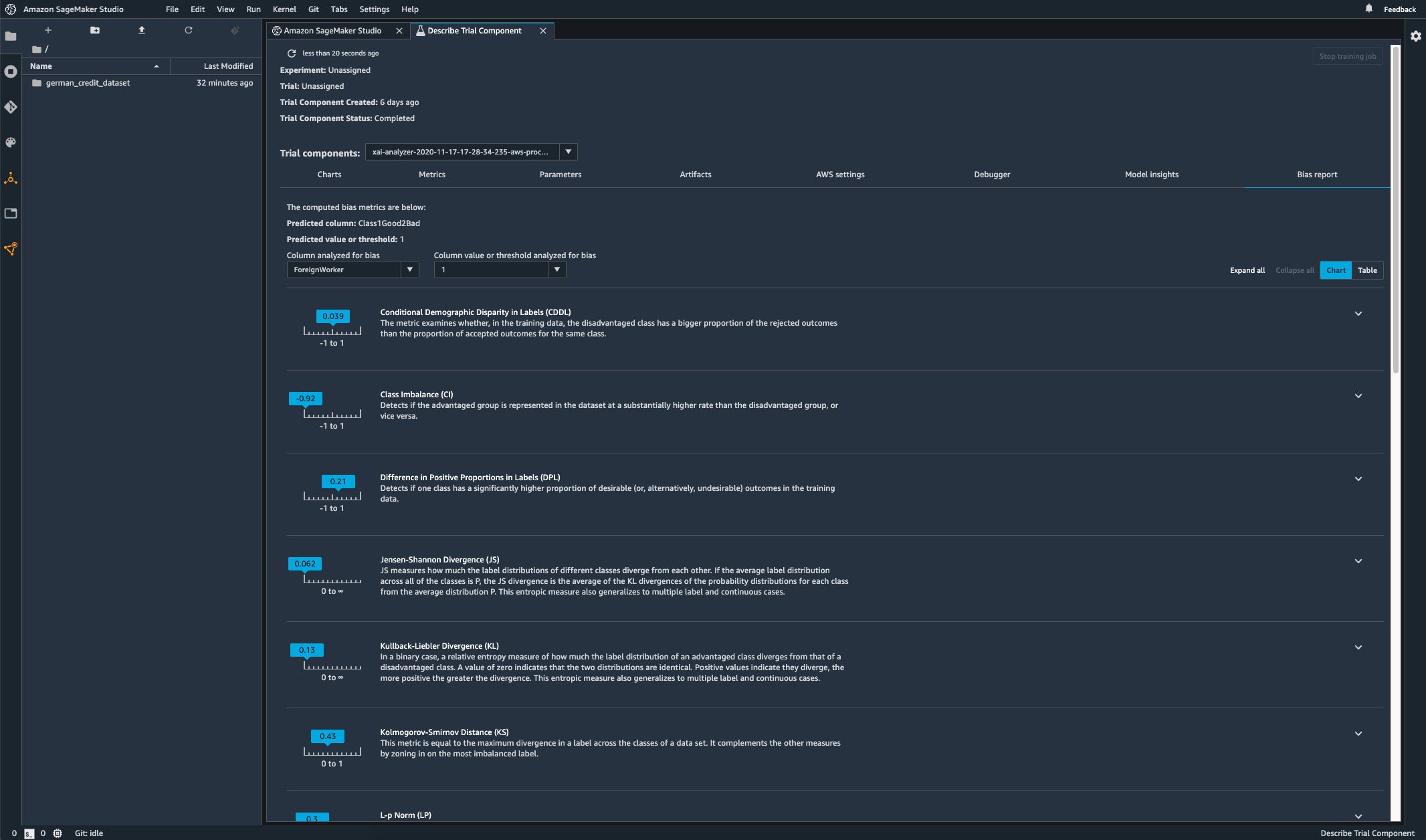
The Bias report is one of the tabs in the Experiments pane. It lists metrics that might indicate biases for the chosen feature, in this case ForeignWorker. The class Imbalance of -0.92 is the same as it was in the original data; in other words, foreign workers are under-represented both in the data and in the model.
 IDG
IDG
The SageMaker Model Monitor can detect biases in inferences in real time. Bias metrics above the orange threshold line indicate possible drifts in the population and may require you to retrain the model.
Amazon SageMaker Debugger
The SageMaker Debugger is a misnomer, but it’s a useful facility for monitoring and profiling training metrics and system resources during machine learning and deep learning training. It allows you to detect common training errors such as inadequate RAM or GPU memory, gradient values exploding or going to zero, over-utilized CPU or GPU, and error metrics starting to rise during training. When it detects specific conditions, it can stop the training or notify you, depending on how you have set up your rules.
SageMaker Debugger supports the most common machine learning frameworks including TensorFlow, PyTorch, Apache MXNet, Keras, and XGBoost. SageMaker’s built-in containers for these frameworks come pre-installed with SageMaker Debugger, enabling you to monitor, profile, and debug your training scripts. You can also use SageMaker Debugger with custom training containers.
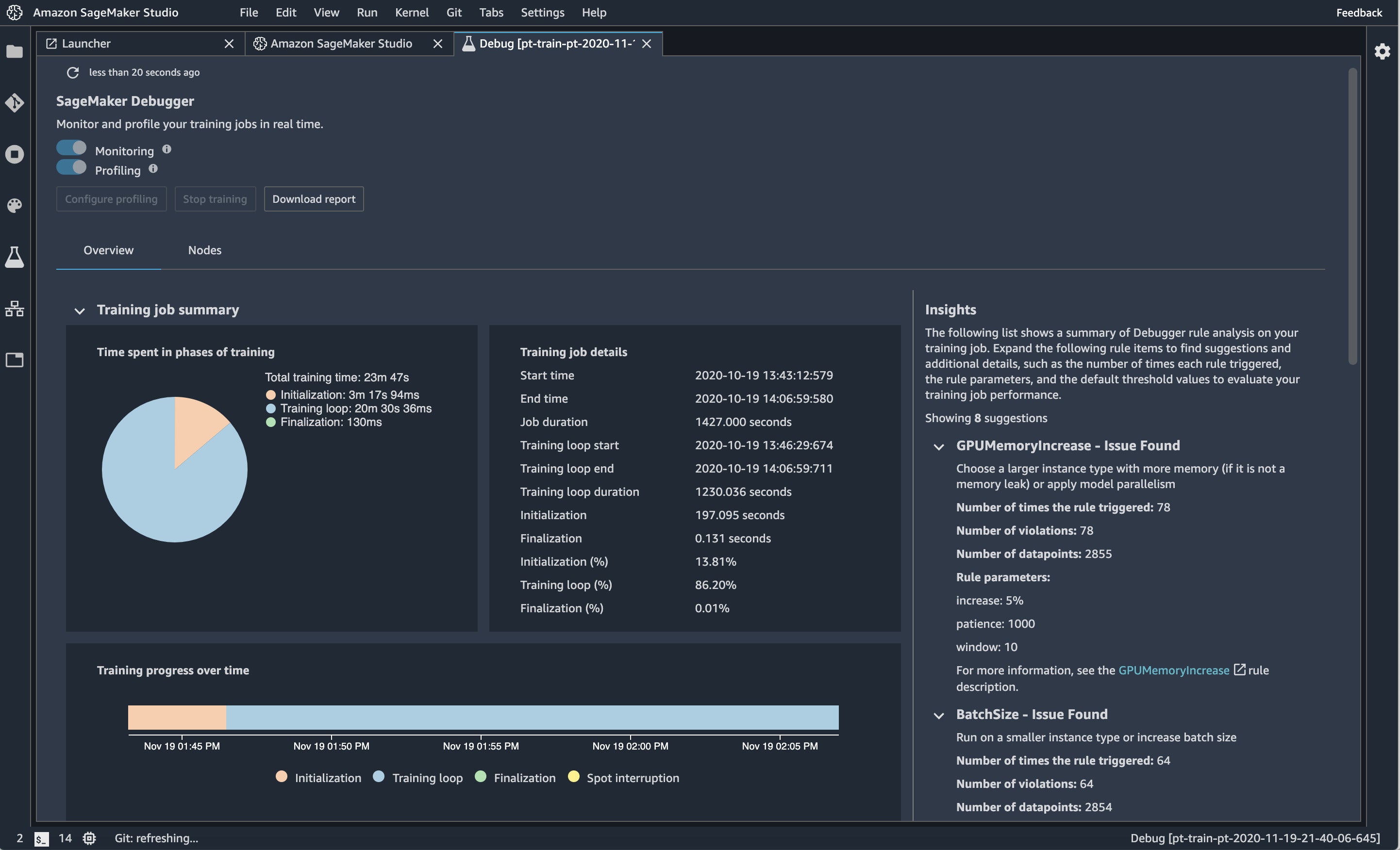 IDG
IDG
One of the ways to monitor your training runs is to view the SageMaker Debugger while your training jobs are running. This particular run triggered eight rules, for which Debugger supplied suggestions.
Amazon SageMaker Model Monitor
While SageMaker Debugger monitors model training, SageMaker Model Monitor monitors an endpoint’s model inference, and lets you know if and when it sees model drift (accuracy dropping over time) or concept drift (the difference between data used to train models and data used during inference). Model Monitor is also integrated with Amazon SageMaker Clarify to improve visibility into potential bias.
 IDG
IDG
SageMaker Model Monitor can detect model and concept drift over time. It can also detect bias drift over time, as shown in the time series graph at the bottom of the screen.
Amazon SageMaker Distributed Training
SageMaker now supports two kinds of distributed training of its own, in addition to the framework-specific APIs for TensorFlow (Horovod) and PyTorch (DDP). Amazon claims a 40% reduction in distributed training time, but I’m not really sure how they came up with that number.
The two distributed training mechanisms address different problems. Data parallelism addresses excessively large amounts of training data by distributing mini-batches across multiple workers and averaging all the gradients after each epoch (the all-reduce step). You should try training on bigger instances with more GPUs and larger GPU memory before resorting to training on multiple VM instances.
Model parallelism addresses large models that don’t fit into a node’s memory in one piece by dividing the neural network up into layers and distributing the layers across nodes. Partitioning a neural network by hand often takes weeks, but SageMaker can split your model in seconds by profiling it with SageMaker Debugger and finding the most efficient way to partition it across GPUs. One of the tricks that SageMaker uses for model parallelism is to construct an interleaved pipeline, prioritizing backward execution of mini-batches whenever possible.
Which mechanism should you use? If you can, use data parallelism. If you still can’t fit the model into the memory of the biggest GPU available to you after trying all the tricks, then try model parallelism. Note that model parallelism saves memory for large models, enabling you to train using batch sizes that previously did not fit in memory.
Amazon SageMaker Pipelines
MLOps is becoming a big deal, finally. (It seems to me that data scientists are at least 10 years behind software developers when it comes to operations.) Amazon claims that the new SageMaker Pipelines product is the first purpose-built, easy-to-use continuous integration and continuous delivery (CI/CD) service for machine learning. I suspect that both Google Cloud and Microsoft Azure disagree with that claim.
SageMaker Pipelines helps you automate different steps of the machine learning workflow, including data loading, data transformation, training and tuning, and deployment. According to AWS, with SageMaker Pipelines you can build dozens of machine learning models weekly, manage massive volumes of data, thousands of training experiments, and hundreds of different model versions. You can share and re-use workflows to recreate or optimize models, helping you scale machine learning throughout your organization.
 IDG
IDG
You can view SageMaker Pipeline graphs in SageMaker Studio, after building them with a Python SDK.
Amazon SageMaker Edge Manager
Edge computing is information processing located near where the data is produced that is also connected to the cloud, often through an edge gateway. You hear about Edge mostly in the context of the Internet of Things. There has been a huge boom in the number and capabilities of edge devices, such as the Nvidia Jetson family of modules for embedded systems, which include GPUs and can run multiple neural networks in parallel while reading input from multiple sensors.
Amazon SageMaker Edge Manager allows you to optimize, secure, monitor, and maintain machine learning models on fleets of smart cameras, robots, personal computers, and mobile devices. It provides a software agent that runs on edge devices, and contains a machine learning model optimized with SageMaker Neo. The agent also collects prediction data and sends a sample of the data to the cloud for monitoring, labeling, and retraining so you can keep models accurate over time. All data can be viewed in the SageMaker Edge Manager dashboard, which reports on the operation of deployed models across your fleet of edge devices.
SageMaker Edge Manager allows you to optimize and package trained models using different frameworks such as Darknet, Keras, Apache MXNet, PyTorch, TensorFlow, TensorFlow Lite, ONNX, and XGBoost for inference on Android, iOS, Linux, and Windows-based machines. It supports gRPC, an open source remote procedure call, which allows you to integrate SageMaker Edge Manager with your existing edge applications through APIs.
AWS AI Services
While SageMaker is primarily for training, deploying, and managing your own models, the AWS AI services are pre-trained and ready to use. In general, it’s more efficient to use a pre-trained service if it does what you need.
Amazon’s non-industry-specific AI services include Amazon Kendra (enterprise search), Amazon Personalize (recommendations), AWS Contact Center Intelligence, Amazon Comprehend (text analytics), Amazon Textract (document analysis), Amazon Translate, Amazon Lookout for Metrics (anomaly detection), Amazon Forecast (demand forecasting), Amazon Fraud Detector, Amazon Lookout for Vision (quality inspection), AWS Panorama (vision at the edge), Amazon Rekognition (image and video analysis), Amazon Polly (text to speech), Amazon Transcribe (speech to text), Amazon Lex (chatbots), Amazon DevOps Guru, Amazon CodeGuru Reviewer (for Java and Python code), and Amazon CodeGuru Profiler (runtime behavior of code).
Amazon Kendra
Amazon Kendra is a managed enterprise search service that enables your users to search unstructured data using natural language. It returns specific answers to three types of questions: factoids (who, what, where, or when), descriptions (how-to), and (with less specificity) keywords.
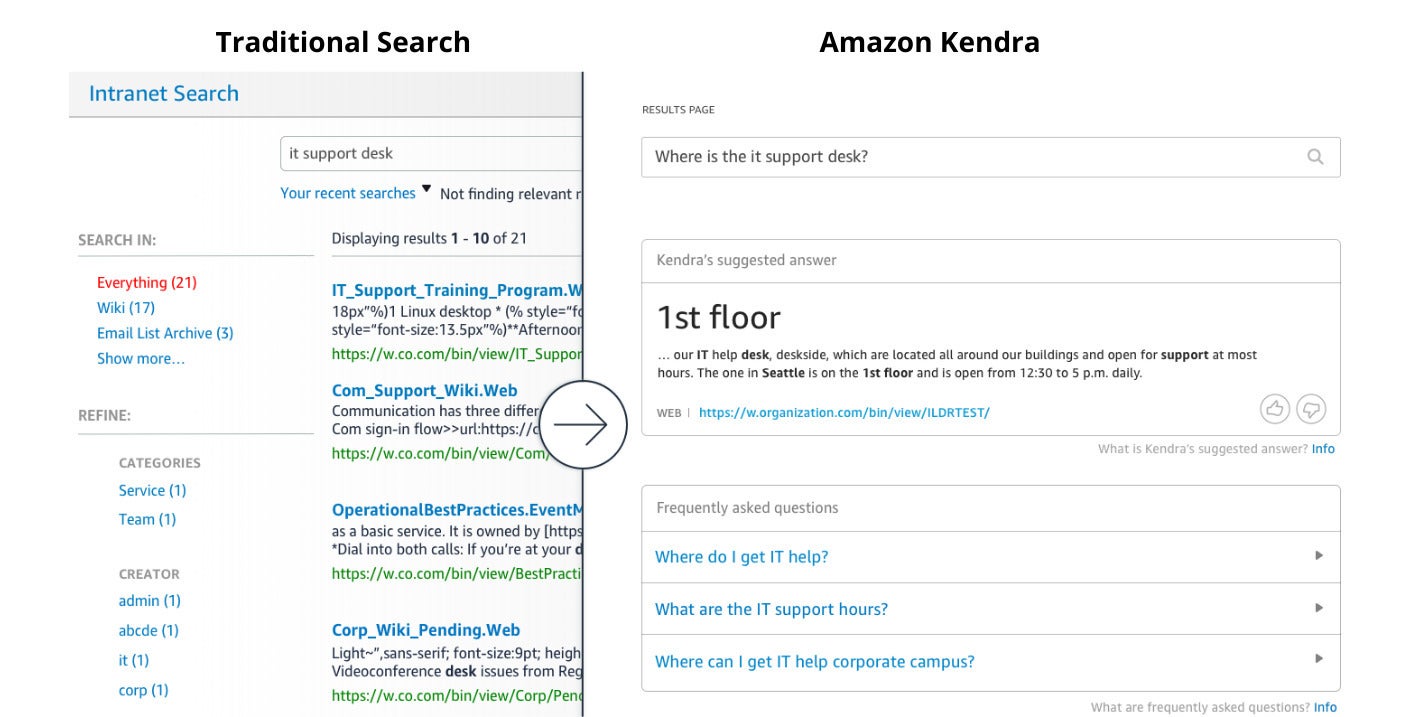 IDG
IDG
By understanding the question asked, Amazon Kendra can return a specific answer instead of everything related to the keywords used.
Amazon Personalize
The classic example of a personalized home page is, of course, Amazon.com, where you will always see products that Amazon thinks you might buy based on your browsing and buying history. Amazon Personalize enables developers to build applications with the same machine learning technology used by Amazon.com for real-time personalized recommendations, without requiring you to know anything about machine learning.
AWS Contact Center Intelligence and Amazon Connect
Amazon Connect is the omni-channel contact center solution that Amazon built for itself a decade ago. It is appropriate if your organization doesn’t yet have a contact center. You need to contact AWS sales for pricing, but you can create an instance and connect it to a telephone number yourself.
AWS Contact Center Intelligence is an add-on to existing contact centers that “offers a variety of ways to quickly and cost effectively add intelligence.” Contact Center Intelligence is available through AWS partners.
Amazon Comprehend
Amazon Comprehend is a managed, pay-as-you-go natural language processing (NLP) service that uses machine learning to find insights and relationships in text. No ML experience is required. Services include Key Phrase Extraction, Sentiment Analysis, Entity Recognition, Language Detection, PII Detection, Event Detection, and Syntax Analysis. Each service is a separate API call.
Custom Comprehend can train a custom NLP model to categorize text and extract custom entities. Topic modeling identifies relevant terms or topics from a collection of documents stored in Amazon S3. There is also a medical version of Comprehend; see the industry-specific services below.
Amazon Textract
Amazon Textract is a managed document processing service with two APIs, Detect Document Text and Analyze Document. It goes beyond optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Textract uses machine learning to read and process any type of document, accurately extracting printed text, handwriting, forms, tables, and other data without the need for manual effort or custom code.
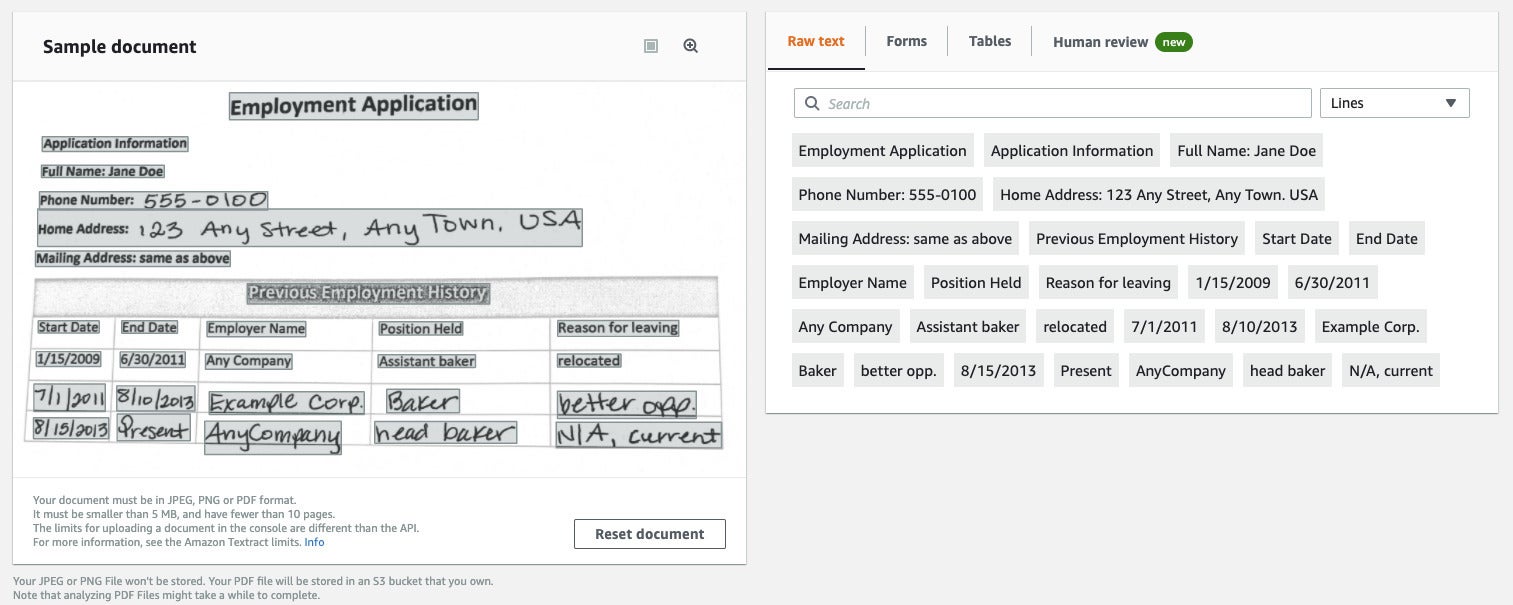 IDG
IDG
The Analyze Document API of the Amazon Textract service not only extracts raw text from an image, but also recognizes forms and tables (see the tabs at the top of the right-hand pane).
Amazon Translate
Amazon Translate is a neural machine translation service. Neural machine translations are typically much better than statistical and rule-based translations. Translate handles 71 languages and variants, roughly as many as Microsoft Azure Translator, but not as many as Google Translate.
You can customize translations with custom terminology and parallel data. Custom terminology, which is useful for getting brand names and technical terms right, requires you to attach a CSV or TMX file to your account, and specify the custom term as part of your translation request. There’s no extra charge for custom terminology.
Parallel data (Active Custom Translation), which is useful for influencing the voice and style of the translation, requires you to upload full translations in CSV, TSV, or TMX format to an S3 bucket, and call a special API that’s four times as expensive as standard translations.
The maximum document size for synchronous translations is 5K UTF-8 characters, but you can divide a large document into sentences to work around this limit. The maximum document size for asynchronous translations is 20 megabytes, but there are other limits as well.
 IDG
IDG
The phrase “Good fresh Russian black bread” is a textbook test of Russian adjective endings. Amazon Translate passed.
Amazon Lookout for Metrics (Preview)
Amazon Lookout for Metrics uses machine learning to automatically detect and diagnose anomalies (outliers from the norm) in business and operational time series data. It connects to Amazon S3, Amazon Redshift, and Amazon Relational Database Service (RDS), as well as third-party SaaS applications, such as Salesforce, ServiceNow, Zendesk, and Marketo.
Lookout for Metrics automatically inspects and prepares the data from these sources and builds a custom machine learning model, informed by over 20 years of experience at Amazon, to detect anomalies. You can also provide feedback on detected anomalies to tune the results and improve accuracy over time.
Lookout for Metrics allows you to diagnose detected anomalies by grouping together anomalies that are related to the same event and sending an alert that includes a summary of the potential root cause. It also ranks anomalies in order of severity.
Amazon Forecast
Amazon Forecast is a managed service that uses automated machine learning to turn historical time series and related data into forecasts. Forecast includes algorithms that are based on over 20 years of forecasting experience at Amazon.com.
Amazon claims that its forecasts are 50% more accurate than ones based strictly on a single historical time series, when external factors are significant, as is often the case; that’s a believable number. Amazon also supplies public weather data to supplement your own data.
Another claim is that Amazon Forecast reduces forecasting time from months to hours. “Months” is an exaggeration, unless Amazon assumes that the forecasters don’t know statistics or machine learning at all and have to learn it from scratch.
Amazon Fraud Detector
Amazon Fraud Detector is a managed service that allows you to identify potentially fraudulent online activities, such as online payment fraud and the creation of fake accounts. Fraud Detector uses automatic machine learning and 20 years of fraud detection expertise from AWS and Amazon.com to automatically identify potentially fraudulent activity.
There are five steps to using Amazon Fraud Detector:
- Define the event you want to evaluate for fraud.
- Upload your historical event dataset to Amazon S3 and select a fraud detection model type.
- Amazon Fraud Detector uses your historical data as input to build a custom model. The service automatically inspects and enriches data, performs feature engineering, selects algorithms, trains and tunes your model, and hosts the model.
- Create rules to either accept, review, or collect more information based on model predictions.
- Call the Amazon Fraud Detector API from your online application to receive real-time fraud predictions and take action based on your configured detection rules.
 IDG
IDG
With Amazon Fraud Detector, first you train a machine learning model on your historical data, and then you create rules to trigger the appropriate actions.
Amazon Lookout for Vision (Preview)
Amazon Lookout for Vision is a machine learning service that spots defects and anomalies in visual representations using computer vision. For example, Amazon Lookout for Vision can be used to identify missing components in products, damage to vehicles or structures, irregularities in production lines, minuscule defects in silicon wafers, and other similar problems.
Lookout for Vision doesn’t require specialized machine vision cameras. It works with five steps:
- Collect images that show normal and defective products from your production line and load them into the Amazon Lookout for Vision console.
- Label images as normal or anomalous and Lookout for Vision will automatically build a model for you in minutes. Tune your model to improve defect detection by adding images to the dataset.
- Use the Amazon Lookout for Vision dashboard to monitor defects and improve processes.
- Automate visual inspection processes in real time or in batch and receive notifications when defects are detected.
- Make continuous improvements by providing feedback on the identified product defects.
At this point, Lookout for Vision sends visual inspection images to the AWS cloud for classification. You can tighten the loop if you set up AWS Outposts servers on-premises so that you can run AWS services locally. But also consider AWS Panorama for computer vision at the edge.
 IDG
IDG
Amazon Lookout for Vision provides a console interface so that you can label your training images. You can also use labeled folders in Amazon S3 for normal and anomalous images.
AWS Panorama (Preview)
While Amazon Lookout for Vision is a cloud service tied to local cameras, AWS Panorama was designed to connect to cameras and provide computer vision at the edge. Panorama is a machine learning appliance and SDK that allows organizations to bring computer vision to on-premises cameras to make predictions locally with high accuracy and low latency.
The AWS Panorama Appliance is a hardware device that allows you to add computer vision to your IP cameras that weren’t built to accommodate computer vision. AWS Panorama Appliance turns your existing cameras into smart cameras that can run computer vision models on multiple concurrent video streams.
The AWS Panorama Device SDK is a software kit that enables third-party manufacturers to build new cameras that run more meaningful computer vision models at the edge for tasks like object detection or activity recognition. AWS Panorama-compatible cameras work out of the box with AWS machine learning services.
Typically you would train your computer vision models on SageMaker, and then run inference at the edge, either on a Panorama Appliance or Panorama-compatible cameras. AWS Panorama can import trained computer vision models from S3, and it uses SageMaker Neo to optimize models to run on the AWS Panorama Appliance.
Amazon Rekognition
Amazon Rekognition is a managed image and video analysis service. It can identify objects, people, text, scenes, and activities in images and videos, as well as detect any inappropriate content (content moderation). Rekognition also provides facial analysis and facial search capabilities that you can use to detect, analyze, and compare faces.
If Rekognition doesn’t do what you need, you can use Rekognition Custom Labels to identify the objects and scenes in images that are specific to your business needs. You need to supply images of objects or scenes you want to identify, and the service takes care of the transfer learning to build a customized model.
In June 2020, Amazon implemented a one-year moratorium on police use of facial recognition. The justification for the one-year period is that it would give legislators time to catch up to technology.
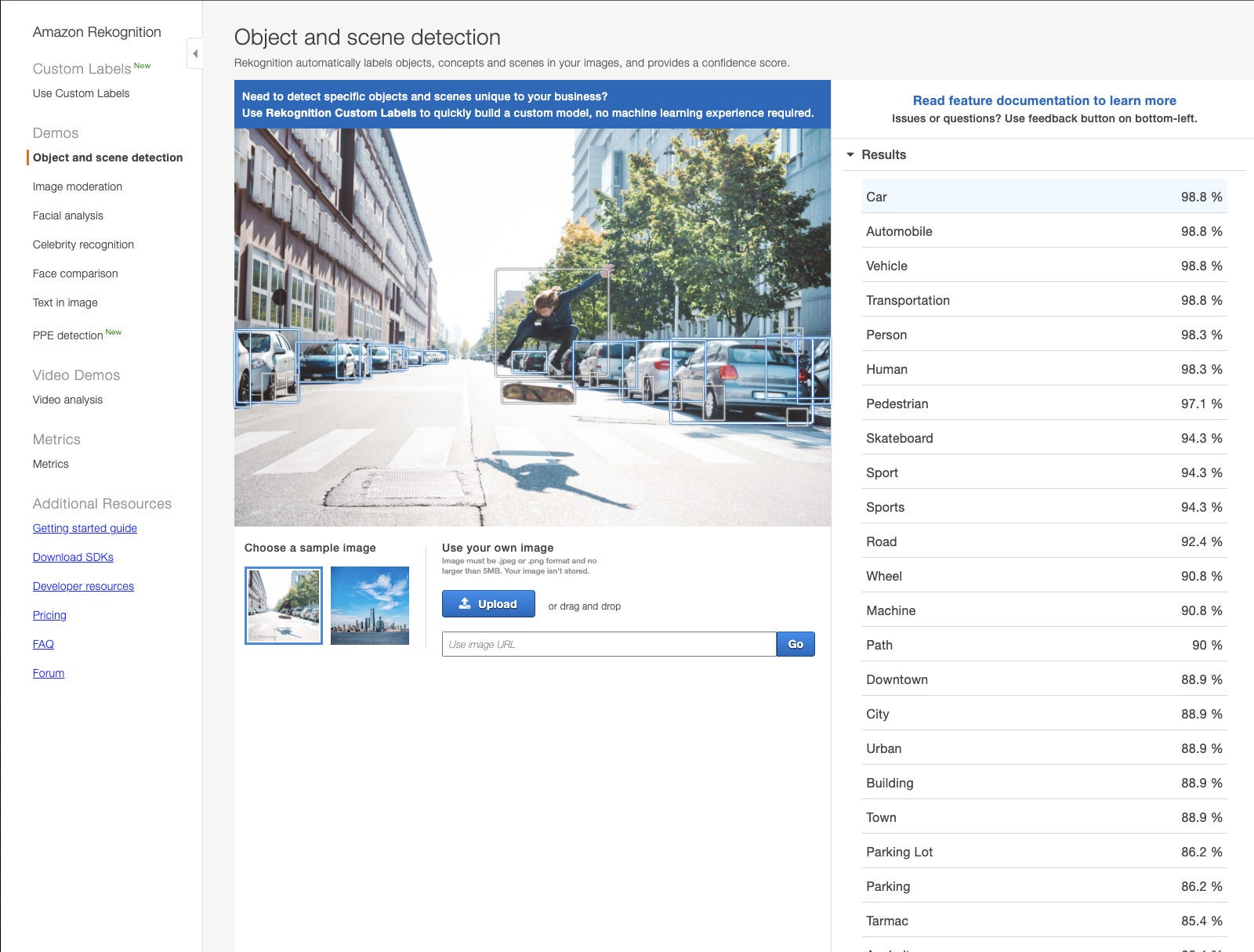 IDG
IDG
Object and scene detection, shown here, is one of about nine APIs available from Amazon Rekognition out of the box. You can also train for custom labels with transfer learning.
Amazon Polly
Amazon Polly is a managed text-to-speech service that includes a selection of standard and neural and male and female voices for over 20 languages and variants. By comparison, Microsoft Azure text-to-speech supports over 50 languages and variants, and Google text-to-speech supports over 40. The pricing of all three services is very close.
The neural voices, produced using deep learning, sound considerably more natural than the standard voices, but cost four times as much to use. A few neural voices are available for newscaster and conversational styles. Also, a few voices have been trained for bilingual use.
Amazon Polly supports Speech Synthesis Markup Language (SSML) with some custom Amazon tags. It supports MP3, Vorbis, and raw PCM audio stream formats at a range of sampling rates from 8 kHz, which sounds pretty bad, to 24 kHz, which is lifelike. You can request speech marks that signify the beginnings of words and sentences to help with highlight or animation synchronization; speech mark requests cost as much as speech requests.
Amazon Transcribe
Amazon Transcribe is a managed pay-as-you-go automatic speech recognition service based on deep learning. (I’ll discuss the specialized version, Transcribe Medical, with the other industry-specific services below.) Transcribe can be used to transcribe customer service calls, automate subtitling, and generate metadata for media assets to create a fully searchable archive.
Amazon Transcribe automatically adds speaker diarization, punctuation, number normalization, and formatting. In my experience, it doesn’t always get these right, especially if the speaker pauses for a breath or stumbles over a word. While there’s certainly a use for Transcribe, it doesn’t quite replace manual transcription services.
There are ways to improve your automatic transcription, however. You can add new words to the base vocabulary to generate more accurate transcriptions for domain-specific words and phrases such as product names, technical terminology, and the names of individuals. You can also specify a list of words to remove from transcripts, such as “uh,” “um,” and profanity.
Amazon Lex
Amazon Lex is a managed service for building conversational interfaces into any application using voice and text. It relies on Amazon Transcribe for voice recognition, and Amazon Comprehend to recognize the intent of the text. You can use Lex to build bots to increase contact center productivity and automate simple tasks. Lex uses the same technologies that power Alexa.
Amazon Lex can call AWS Lambda functions to do things like look up prices and make reservations. It can also support multi-turn conversations, so that it can fill in parameters that turn an initial intent such as “I want to book a room” to a specific request such as “Book a non-smoking room with a king-size bed at the Boston Marriott Long Wharf for two adults on Thursday night at the AARP discount rate.”
Amazon DevOps Guru (Preview)
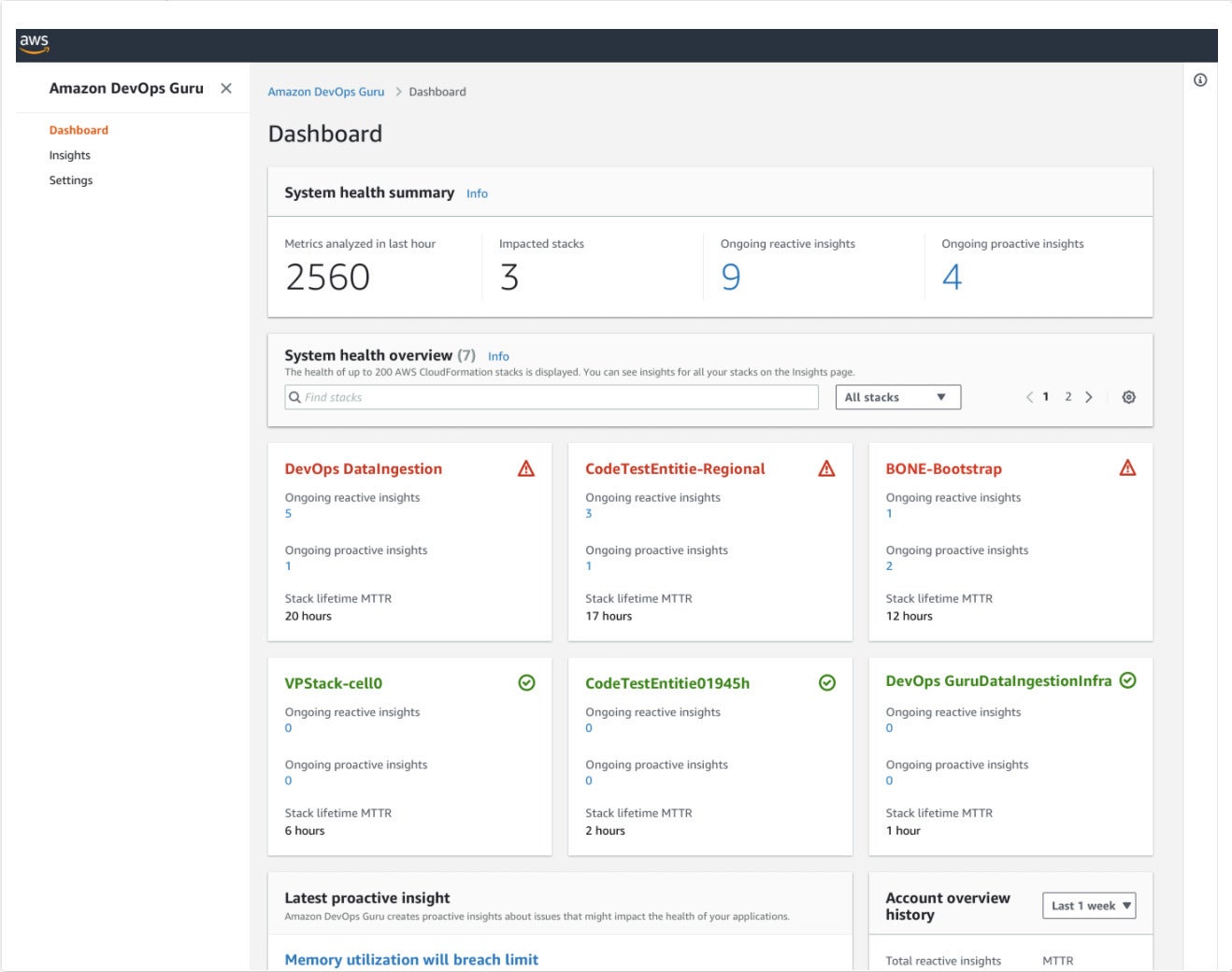
There are few organizations that have as much experience with application operations as AWS and Amazon.com. Amazon DevOps Guru is a managed service that detects behaviors that deviate from normal operating patterns so you can identify operational issues before they impact your customers. DevOps Guru uses machine learning models trained on internal AWS operational data to provide accurate operational insights for critical issues that impact applications.
 IDG
IDG
Amazon DevOps Guru monitors your software stacks and provides both reactive and proactive insights. You can configure the system to alert you to critical deviations from the norm, such as memory leaks.
Amazon CodeGuru Reviewer and Profiler (Preview)
Amazon CodeGuru has two components: Reviewer to improve your code quality, and Profiler to identify an application’s most expensive lines of code.
Amazon CodeGuru Reviewer doesn’t necessarily replace human peer review, but augments it. You add Reviewer to your repository as one of the designated code reviewers. It works for Java and Python, initially analyzes whole repositories, and then analyzes pull requests as they come in, using machine learning, AWS and security best practices, and hard-learned lessons across millions of code reviews for thousands of open-source and Amazon repositories.
Amazon CodeGuru Profiler optimizes performance for applications running in production and identifies the most expensive lines of code. It is always searching for application performance optimizations, recommending ways to fix them to reduce CPU utilization, cut compute costs, and improve application performance.
AWS Industry Specific Solutions
There’s actually significant overlap between industry-specific solutions and standard AI services. AWS Panorama and Amazon Lookout for Vision, for example, could easily be classed in both categories — and AWS does that in its marketing materials. Nevertheless, I have included Amazon Monitron, Amazon Lookout for Equipment, Amazon Healthlake, Amazon Comprehend Medical, and Amazon Transcribe Medical in this category.
Amazon Monitron
Amazon Monitron is an end-to-end system that uses machine learning to detect abnormal behavior in industrial machinery, enabling you to implement predictive maintenance and reduce unplanned downtime. Monitron includes sensors to capture vibration and temperature data from equipment, a gateway device to securely transfer data to AWS, the service that analyzes the data for abnormal machine patterns using machine learning, and a companion mobile app to set up the devices and receive reports on operating behavior and alerts to potential failures in your machinery. This is the same technology used to monitor equipment in Amazon Fulfillment Centers.
Amazon Lookout for Equipment (Preview)
Amazon Lookout for Equipment uses the data from your existing sensors to detect abnormal equipment behavior, so you can take action before machine failures occur and avoid unplanned downtime. It analyzes the data from your sensors, such as pressure, flow rate, RPMs, temperature, and power, to automatically train a specific machine learning model based on just your data, for your equipment, with no machine learning expertise required on your end.
Amazon Healthlake (Preview)
Amazon HealthLake is a HIPAA-eligible service that enables healthcare providers, health insurance companies, and pharmaceutical companies to store, transform, query, and analyze health data at petabyte scale. It removes the heavy lifting of organizing, indexing, and structuring patient information to provide a complete view of the health of individual patients and entire patient populations in a secure, compliant, and auditable manner.
Using the Amazon HealthLake APIs, healthcare organizations can easily copy health data in the Fast Healthcare Interoperability Resources (FHIR) industry standard format from on-premises systems to a secure data lake in the cloud. HealthLake transforms unstructured data using specialized machine learning models, like natural language processing, to automatically extract meaningful medical information from the data and provides powerful query and search capabilities.
Amazon Comprehend Medical
Amazon Comprehend Medical is a HIPAA-eligible natural language processing (NLP) service that uses machine learning to extract health data from medical text, with no machine learning experience required. With an API call to Amazon Comprehend Medical you can extract information such as medical conditions, medications, dosages, tests, treatments and procedures, and protected health information, while retaining the context of the information.
Amazon Comprehend Medical can identify the relationships among the extracted information to help you build applications for use cases like population health analytics, clinical trial management, pharmacovigilance, and summarization. You can also use Comprehend Medical to link the extracted information to medical ontologies such as ICD-10-CM or RxNorm to help you build applications for revenue cycle management (medical coding), claim validation and processing, and electronic health record creation.
Amazon Transcribe Medical
Amazon Transcribe Medical is an automatic speech recognition service that lets you add medical speech-to-text capabilities to your voice-enabled applications. It provides accurate speech-to-text for use cases such as voice scribes for clinical documentation, call analytics in pharmacovigilance, subtitling, and accessibility during telehealth sessions. Transcribe Medical supports transcription for different specialties, which you can specify when you start a stream. There are different settings for clinician-patient dialogue and post medical encounter dictation.
AWS provides a broad and deep portfolio of machine learning infrastructure services with a choice of processors and accelerators to meet your unique performance and budget needs. Amazon EC2 P4d instances provide the highest performance for machine learning training in the cloud with the latest Nvidia A100 Tensor Core GPUs coupled with 400 Gbps instance networking. P4d instances are deployed in hyperscale clusters, called EC2 UltraClusters, offering supercomputer-class performance for the most complex machine learning training jobs. For inference, Amazon EC2 Inf1 instances, powered by AWS Inferentia chips, provide high-performance and low-cost inference.
You can choose from TensorFlow, PyTorch, Apache MXNet, and other popular frameworks to experiment with and customize machine learning algorithms. You can use the framework of your choice as a managed experience in Amazon SageMaker, or use the AWS Deep Learning AMIs (Amazon machine images), which are fully configured with the latest versions of the most popular deep learning frameworks and tools.
Choosing AWS for AI and machine learning
As we’ve seen, Amazon Web Services provides a broad and deep set of machine learning and AI services. AWS AI and Machine Learning is competitive with Google Cloud AI and Machine Learning and Microsoft Azure AI and Machine Learning in the areas of ready-to-use AI services, AI service customization, data science in Jupyter notebooks, and infrastructure. There are a few areas of differentiation, however.
For example, AWS recently announced some interesting new initiatives for industrial and medical AI services, although most of them are still in preview. AWS does have more data centers in place than either Google Cloud or Microsoft Azure, but for data scientists in most populated first-world locations that doesn’t really matter.
AWS has the new SageMaker Data Wrangler to help with the first steps in model building. Google uses a third-party product for this. Microsoft Azure has an easy drag-and-drop pipeline builder, and also has an integrated Databricks implementation.
Right now Microsoft Azure seems to be a little better than AWS or Google Cloud for creating new vision models with transfer learning because it needs fewer training images to get to the same accuracy and recall, and seems to be a little ahead in the area of Responsible AI. I have no idea whether those differences will last long. AWS is a little bit behind Google Cloud in the number of languages it can translate, and behind both Microsoft Azure and Google Cloud in the number of languages that it supports for text to speech. But what matters there is whether the languages you need are supported, not the overall count.
Microsoft Azure allows users to run some AI services in containers on-premises, which can be a cheap way to bring the services to the data and maintain data security. AWS offers AWS Outposts servers you can run in your own data centers, but those are currently big and expensive; the planned 1U and 2U form factors are promised for later in 2021.
Overall, however, these distinctions are minor and likely to change over time. Right now, you can’t go far wrong using machine learning and AI services from any of the big three cloud services.
—
Pricing
Amazon SageMaker: Free tier, 2 months; notebooks, $0.05 to $6.45/hour depending on instance size; training clusters additional.
Amazon Kendra: Free tier, 750 hours for the first 30 days; Developer Edition, $2.50/hour; Enterprise Edition, $7/hour.
Amazon Personalize: Free tier, 2 months; ingestion ($0.05 per GB), training ($0.24 per training hour), and inference ($0.20 per TPS-hour) are charged separately.
AWS Contact Center Intelligence: Contact AWS sales or an AWS partner.
Amazon Comprehend: Free tier, 50K units of text (5M characters); $0.0001/unit/service with volume discounts. A unit is 100 characters, with a 3 unit minimum per request.
Amazon Textract: Free tier, 3 months, limited to 1K pages per month using the Detect Document Text API and 100 pages per month using the Analyze Document API; after that $1.50 to $65/1K pages with quantity discount.
Amazon Translate: Free tier, 2 million characters per month for 12 months; standard $15/M characters; active custom $60/M characters.
Amazon Lookout for Metrics: Currently in free preview. After that, Free tier will allow tracking 100 metrics for one month. Production costs will be $0.75/metric/month with volume discounts.
Amazon Forecast: Free tier, two months, limit 10K forecasts per month; after that $0.60/1K forecasts, $0.088/GB storage, and $0.24 per training hour.
Amazon Fraud Detector: Free tier, 2 months, with some usage limits; model training $0.39/hour, model hosting $0.06/hour, predictions $0.03 each with volume discounts.
Amazon Lookout for Vision: Free tier, 3 months, limited to 10 training hours and 4 inference hours per month; after that $2.00 per training hour and $4.00 per inference hour with volume discounts.
AWS Panorama: AWS Panorama Appliance Developer Kit, $2,499 per device; AWS Panorama Appliance, $4,000 per device, $8.33 per month per active camera stream.
Amazon Rekognition: Free tier, 12 months, 5K images a month; image analysis, $1/1K API calls with volume discounts; face metadata storage, $0.00001/face per month; video analysis, $0.10/API/minute.
Amazon Polly: Free tier, 12 months, 5M characters a month; standard voices, $4/M characters; neural voices, $16/M characters.
Amazon Transcribe: Free tier, 12 months, 60 audio minutes per month; after that, $0.024/minute with volume discounts; Transcribe Medical $0.075 per minute.
Amazon Lex: Free tier, 12 months, 10K text requests and 5K speech requests or speech intervals per month; after that, $4/1K speech requests and $0.75/1K text requests.
Amazon DevOps Guru: $0.40 per 10K API Calls, plus $0.0028 to $0.0042 per resource per hour analyzed, plus any SNS or System manager notifications used.
Amazon CodeGuru: 90 days free; Reviewer, $0.50 per 100 lines of repository code analyzed with a volume discount, plus $0.75 per 100 lines of pull request code analyzed; Profiler, $0.005 per sampling hour for the first 36,000 sampling hours per profiling group per month, free after that.
Amazon Monitron: Starter Kit (5 Sensors, 1 Gateway), $715; Service, $50 per sensor per year.
Amazon Lookout for Equipment: 1 month free; Data Ingestion, $0.20 per GB; Model Training, $0.24 per training hour; Scheduled Inference, $0.25 per inference hour.
Amazon Healthlake: $0.27 per Data Store hour, and your first 10 GB of storage and 3,500 FHIR queries per hour are included for free. Additional charges: data storage, $0.25/GB/month; queries, $0.015/per 10K queries, per hour; medical NLP, $0.001 per 100 characters; FHIR export, $0.19/GB.
Amazon Comprehend Medical: Free tier, 3 months, 25K units of text (2.5M characters); Medical Named Entity and Relationship Extraction (NERe) API, $0.01/unit; Medical Protected Health Information Data Extraction and Identification (PHId) API, $0.0014/unit; Medical ICD-10-CM Ontology Linking API, $0.0005/unit; Medical RxNorm Ontology Linking API, $0.00025/unit.
Platform
Hosted on Amazon Web Services; dedicated on-premises hardware options available for sale or lease.
"machine" - Google News
February 24, 2021 at 06:00PM
https://ift.tt/2Nzm07K
Review: AWS AI and Machine Learning stacks up - InfoWorld
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Review: AWS AI and Machine Learning stacks up - InfoWorld"
Post a Comment