
{kind=link}
There's a moment in any foray into new technological territory that you realize you may have embarked on a Sisyphean task. Staring at the multitude of options available to take on the project, you research your options, read the documentation, and start to work—only to find that actually just defining the problem may be more work than finding the actual solution.
Reader, this is where I found myself two weeks into this adventure in machine learning. I familiarized myself with the data, the tools, and the known approaches to problems with this kind of data, and I tried several approaches to solving what on the surface seemed to be a simple machine learning problem: Based on past performance, could we predict whether any given Ars headline will be a winner in an A/B test?
Things have not been going particularly well. In fact, as I finished this piece, my most recent attempt showed that our algorithm was about as accurate as a coin flip.
But at least that was a start. And in the process of getting there, I learned a great deal about the data cleansing and pre-processing that goes into any machine learning project.
Prepping the battlefield
Our data source is a log of the outcomes from 5,500-plus headline A/B tests over the past five years—that's about as long as Ars has been doing this sort of headline shootout for each story that gets posted. Since we have labels for all this data (that is, we know whether it won or lost its A/B test), this would appear to be a supervised learning problem. All I really needed to do to prepare the data was to make sure it was properly formatted for the model I chose to use to create our algorithm.
I am not a data scientist, so I wasn't going to be building my own model anytime this decade. Luckily, AWS provides a number of pre-built models suitable to the task of processing text and designed specifically to work within the confines of the Amazon cloud. There are also third-party models, such as Hugging Face, that can be used within the SageMaker universe. Each model seems to need data fed to it in a particular way.
The choice of the model in this case comes down largely to the approach we'll take to the problem. Initially, I saw two possible approaches to training an algorithm to get a probability of any given headline's success:
- Binary classification: We simply determine what the probability is of the headline falling into the "win" or "lose" column based on previous winners and losers. We can compare the probability of two headlines and pick the strongest candidate.
- Multiple category classification: We attempt to rate the headlines based on their click-rate into multiple categories—ranking them 1 to 5 stars, for example. We could then compare the scores of headline candidates.
The second approach is much more difficult, and there's one overarching concern with either of these methods that makes the second even less tenable: 5,500 tests, with 11,000 headlines, is not a lot of data to work with in the grand AI/ML scheme of things.
So I opted for binary classification for my first attempt, because it seemed the most likely to succeed. It also meant the only data point I needed for each headline (beside the headline itself) is whether it won or lost the A/B test. I took my source data and reformatted it into a comma-separated value file with two columns: titles in one, and "yes" or "no" in the other. I also used a script to remove all the HTML markup from headlines (mostly some <em> and a few <i> tags). With the data cut down almost all the way to essentials, I uploaded it into SageMaker Studio so I could use Python tools for the rest of the preparation.
Next, I needed to choose the model type and prepare the data. Again, much of data preparation depends on the model type the data will be fed into. Different types of natural language processing models (and problems) require different levels of data preparation.
After that comes “tokenization.” AWS tech evangelist Julien Simon explains it thusly: “Data processing first needs to replace words with tokens, individual tokens.” A token is a machine-readable number that stands in for a string of characters. “So ’ransomware’ would be word one,” he said, “‘crooks’ would be word two, ‘setup’ would be word three….so a sentence then becomes a sequence of tokens and you can feed that to a deep learning model and let it learn which ones are the good ones, which one are the bad ones.”
Depending on the particular problem, you may want to jettison some of the data. For example, if we were trying to do something like sentiment analysis (that is, determining if a given Ars headline was positive or negative in tone) or grouping headlines by what they were about, I would probably want to trim down the data to the most relevant content by removing "stop words"—common words that are important for grammatical structure but don't tell you what the text is actually saying (like most articles).
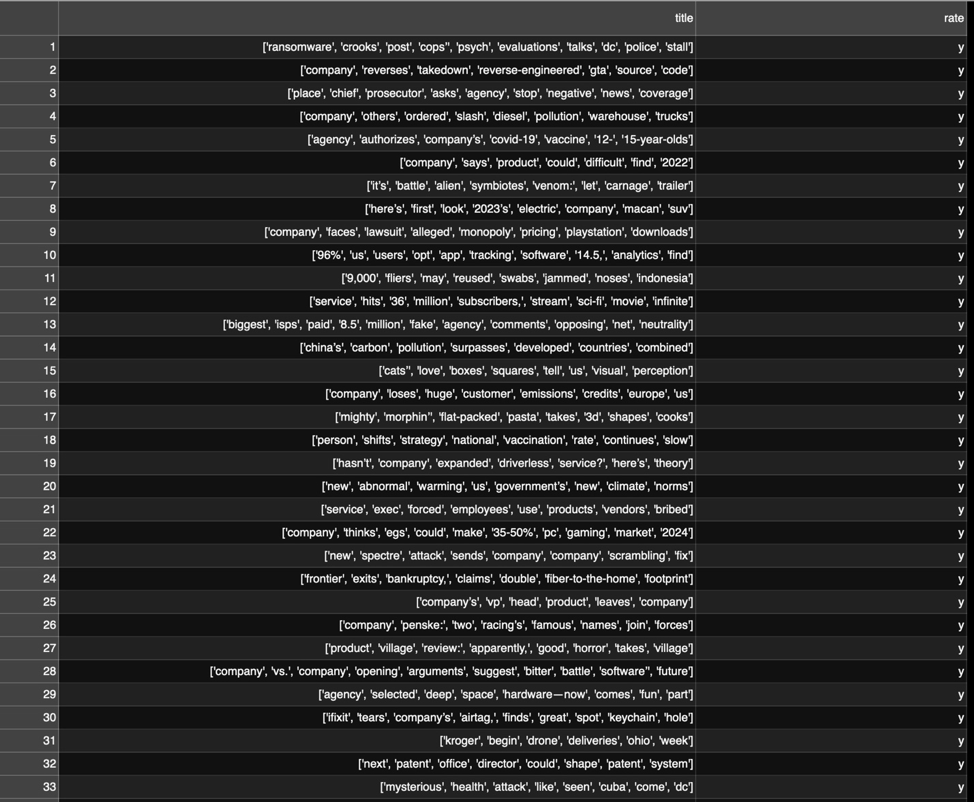
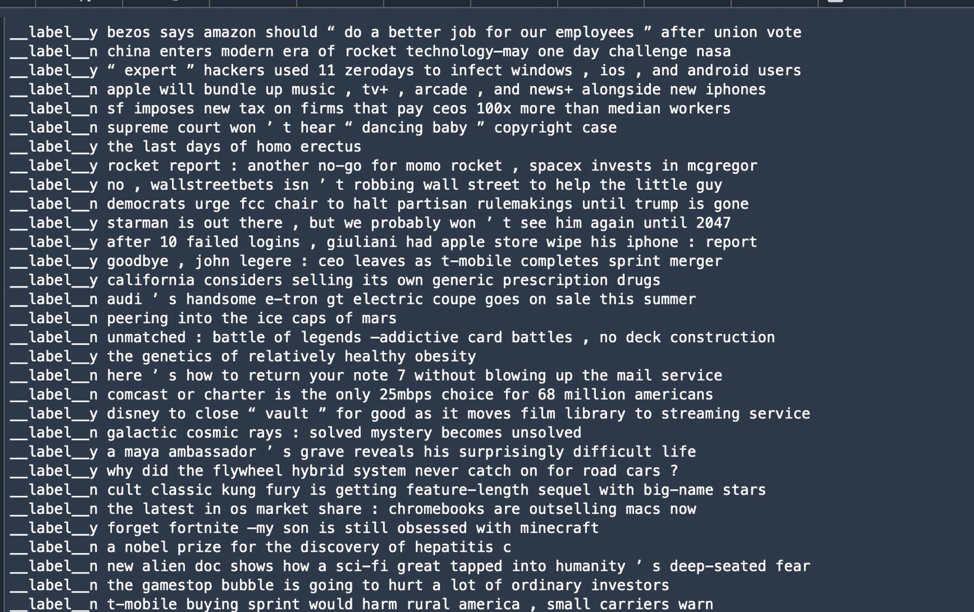
nltk). Notice punctuation sometimes gets packaged with words as a token; this would have to be cleaned up for some use cases.However, in this case, the stop words were potentially important parts of the data—after all, we're looking for structures of headlines that attract attention. So I opted to keep all the words. And in my first attempt at training, I decided to use BlazingText, a text processing model that AWS demonstrates in a similar classification problem to the one we're attempting. BlazingText requires the "label" data—the data that calls out a particular bit of text's classification—to be prefaced with "__label__". And instead of a comma-delimited file, the label data and the text to be processed are put in a single line in a text file, like so:
Another part of data preprocessing for supervised training ML is splitting the data into two sets: one for training the algorithm, and one for validation of its results. The training data set is usually the larger set. Validation data generally is created from around 10 to 20 percent of the total data.
There's been a great deal of research into what is actually the right amount of validation data—some of that research suggests that the sweet spot relates more to the number of parameters in the model being used to create the algorithm rather than the overall size of the data. In this case, given that there was relatively little data to be processed by the model, I figured my validation data would be 10 percent.
In some cases, you might want to hold back another small pool of data to test the algorithm after it's validated. But our plan here is to eventually use live Ars headlines to test, so I skipped that step.
To do my final data preparation, I used a Jupyter notebook—an interactive web interface to a Python instance—to turn my two-column CSV into a data structure and process it. Python has some decent data manipulation and data science specific toolkits that make these tasks fairly straightforward, and I used two in particular here:
pandas, a popular data analysis and manipulation module that does wonders slicing and dicing CSV files and other common data formats.sklearn(orscikit-learn), a data science module that takes a lot of the heavy lifting out of machine learning data preprocessing.nltk, the Natural Language Toolkit—and specifically, thePunktsentence tokenizer for processing the text of our headlines.- The
csvmodule for reading and writing CSV files.
Here’s a chunk of the code in the notebook that I used to create my training and validation sets from our CSV data:
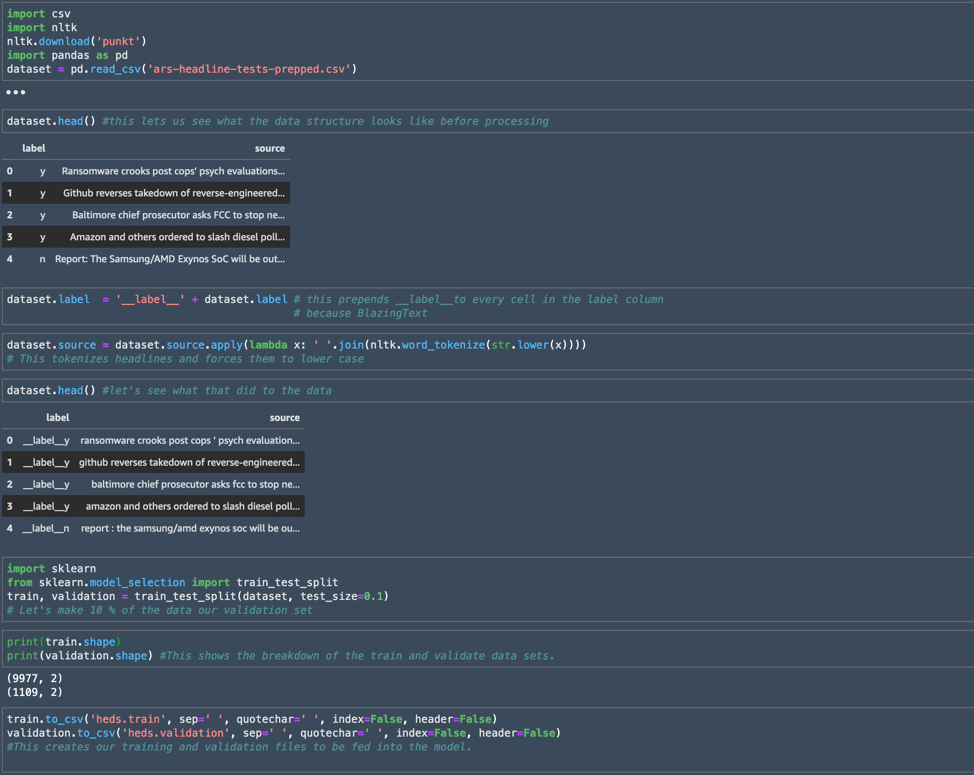
I started by using pandas to import the data structure from the CSV created from the initially cleaned and formatted data, calling the resulting object "dataset." Using the dataset.head() command gave me a look at the headers for each column that had been brought in from the CSV, along with a peek at some of the data.
The pandas module allowed me to bulk add the string "__label__" to all the values in the label column as required by BlazingText, and I used a lambda function to process the headlines and force all the words to lower case. Finally, I used the sklearn module to split the data into the two files I would feed to BlazingText.
Trying a hail Mary
Before firing off my BlazingText job, I wanted to see if I could just load the cleaned-up original working CSV and get a machine learning win using SageMaker's Autopilot function. Autopilot can create an experiment that will automatically consume a CSV or other table of data and generate candidate models to solve three types of machine learning problems—binary classification just happens to be one of them. Autopilot will then iterate through 250 candidate models and tune them in an attempt to improve accuracy.
 Setting up an Autopilot experiment.
Setting up an Autopilot experiment. The Autopilot experiment begins.
The Autopilot experiment begins.
This menu-driven process can take a data file and try multiple types of models against it automatically, chunking the data into testing and validation sets and running it through multiple models and performing automated tuning of the models based on the desired goal. You can choose to just generate the candidates or run the full experiment, and—if you're feeling lucky—you can then choose to automatically deploy the best candidate as a cloud endpoint.
I was not feeling that lucky, but I wanted to see what kind of accuracy I could get out of a purely automatic approach. The best results from Autopilot came from an XGBoost algorithm, which after tuning resulted in an accuracy rate of…around 54 percent. Not great.
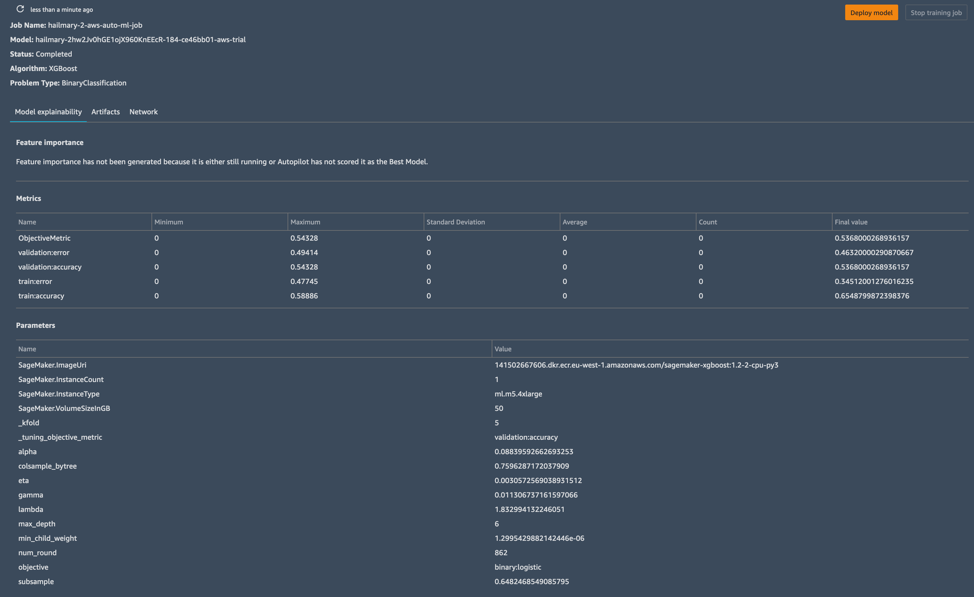
This time for sure (?)
With the random (and somewhat costly, in terms of AWS credits!) appeal to the machines for a quick answer out of the way, I moved on with BlazingText. With some help getting past some initial mistakes from Amazon's Julien Simon, I got the Jupyter notebook ready to kick off things in manual mode.
First, I needed to add some SageMaker incantations to my notebook:
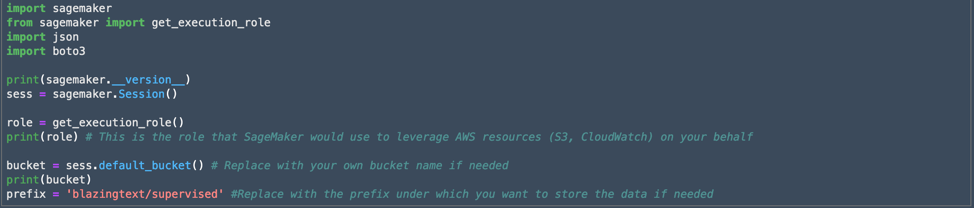
The sagemaker and boto3 modules are specially-built Python extensions used for interacting with the AWS cloud and SageMaker's machine learning systems. The print commands here were to verify the version of the SageMaker API installed and to check the AWS role that would be used to access other AWS resources. Development on the API moves pretty quickly. On my first attempt (leveraging examples I had found through the power of Google), I found several functions in the module apparently had new names.
The next block of code points the training session to the training and validation data chunks I created earlier, and it indicates where the output for the training session should go. To keep track of things so I could grab them later, I printed the S3 container name for the output bucket.
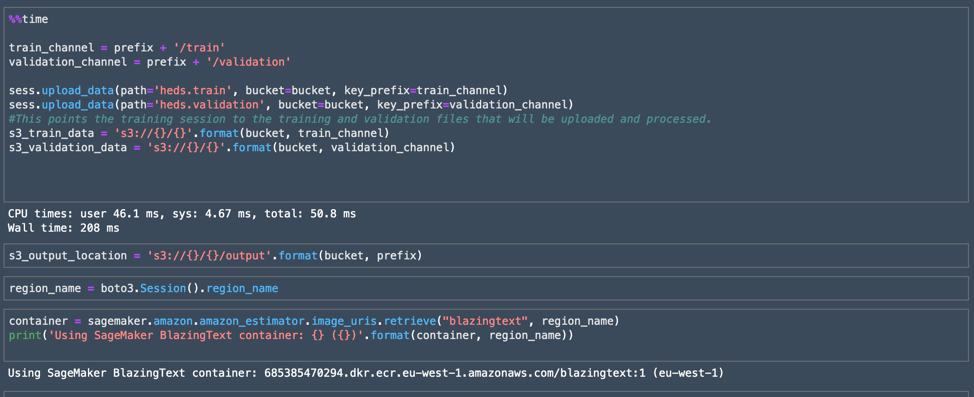
With all of the AWS housekeeping out of the way, it was time to set up the actual ML training session. In this case, I was using none of the "hyperparameters" that could be used to tune the model; I wanted to establish how well the model alone did with the data first. The SageMaker Estimator object contains all of the housekeeping information for setting up the session itself.
The "fit" method in the final cell below launched the job, and the notebook reported back its progress:
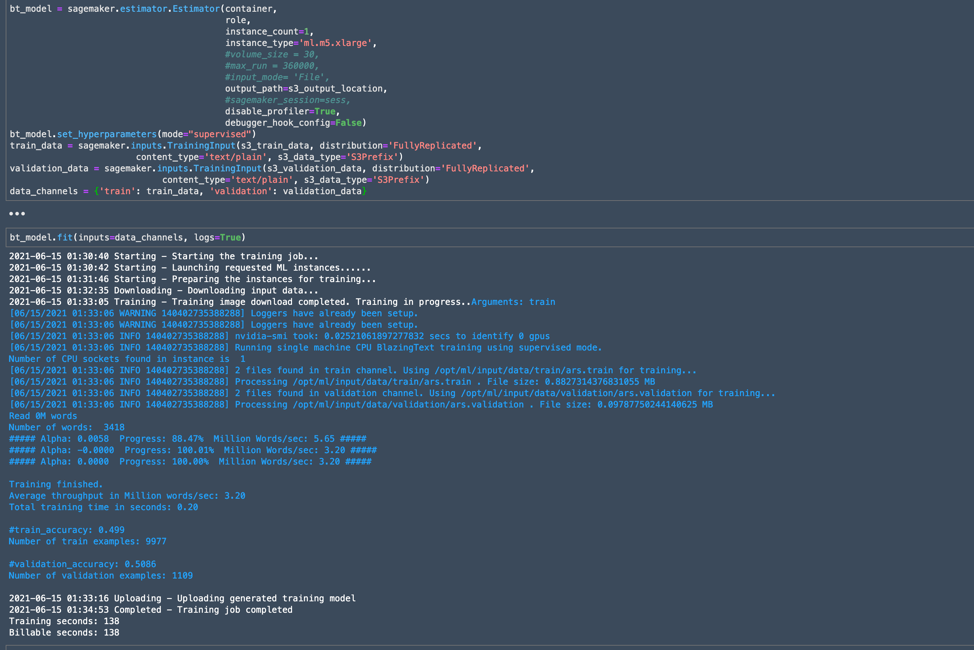
And, oof. Accuracy of the model turned out once again to be that of a coin-toss.
Remaining options
There were a few things Past Sean could have tried to do at this point to improve the outcome from BlazingText. First, I could have checked to see if tweaking the source data any further would help with accuracy—fixing any issues where punctuation marks have fouled the text tokenization, for example.
The next step would be to start adjusting the model's hyperparameters—settings that impact how the machine learning process "learn" the parameters within the training data. BlazingText has 10 different hyperparameters, some with a wide range of possible values.
It's doubtful that any tweaks I made to the hyperparameters would have pushed the accuracy of the learned algorithm much more than a few percentage points, however. So I had to put some time into investigating other appropriate text processing models, such as HuggingFace.
But Past Sean was most disheartened by the possibilities that I'd feared in the first place—primarily that I may just not have brought enough data to work with to get the accuracy we hoped for. Or, perhaps in spite of a user-determined confidence interval in the A/B test outcomes, the variance between the winning and losing headlines may in fact be as random as a coin flip.
If it was the former holding us back—that our hyperparameters just needed tweaking—I thought I might be able to call in reinforcements and find another machine learning path to success. If it's the latter—well, I had a plan to pull in a bit more data, but perhaps not enough to make a difference. I continued plugging away at the model, but I also knew it was time to consult the experts.
As it turns out, there were a few things I was missing. We'll get into that in parts three and four of this grand experience; tune in next week.
"machine" - Google News
July 15, 2021 at 10:00PM
https://ift.tt/2VG6WJ3
Feeding the machine: We give an AI some headlines and see what it does - Ars Technica
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Feeding the machine: We give an AI some headlines and see what it does - Ars Technica"
Post a Comment