
{kind=link}
Every day, some little piece of logic constructed by very specific bits of artificial intelligence technology makes decisions that affect how you experience the world. It could be the ads that get served up to you on social media or shopping sites, or the facial recognition that unlocks your phone, or the directions you take to get to wherever you're going. These discreet, unseen decisions are being made largely by algorithms created by machine learning (ML), a segment of artificial intelligence technology that is trained to identify correlation between sets of data and their outcomes. We've been hearing in movies and TV for years that computers control the world, but we've finally reached the point where the machines are making real autonomous decisions about stuff. Welcome to the future, I guess.
In my days as a staffer at Ars, I wrote no small amount about artificial intelligence and machine learning. I talked with data scientists who were building predictive analytic systems based on terabytes of telemetry from complex systems, and I babbled with developers trying to build systems that can defend networks against attacks—or, in certain circumstances, actually stage those attacks. I've also poked at the edges of the technology myself, using code and hardware to plug various things into AI programming interfaces (sometimes with horror-inducing results, as demonstrated by Bearlexa).
Many of the problems to which ML can be applied are tasks whose conditions are obvious to humans. That's because we're trained to notice those problems through observation—which cat is more floofy or at what time of day traffic gets the most congested. Other ML-appropriate problems could be solved by humans as well given enough raw data—if humans had a perfect memory, perfect eyesight, and an innate grasp of statistical modeling, that is.
But machines can do these tasks much faster because they don't have human limitations. And ML allows them to do these tasks without humans having to program out the specific math involved. Instead, an ML system can learn (or at least "learn") from the data given to it, creating a problem-solving model itself.
This bootstrappy strength can also be a weakness, however. Understanding how the ML system arrived at its decision process is usually impossible once the ML algorithm is built (despite ongoing work to create explainable ML). And the quality of the results depends a great deal on the quality and the quantity of the data. ML can only answer questions that are discernible from the data itself. Bad data or insufficient data yields inaccurate models and bad machine learning.
Despite my prior adventures, I've never done any actual building of machine-learning systems. I'm a jack of all tech trades, and while I'm good on basic data analytics and running all sorts of database queries, I do not consider myself a data scientist or an ML programmer. My past Python adventures are more about hacking interfaces than creating them. And most of my coding and analytics skills have, of late, been turned toward exploiting ML tools for very specific purposes related to information security research.
My only real superpower is not being afraid to try and fail. And with that, readers, I am here to flex that superpower.
The task at hand
Here is a task that some Ars writers are exceptionally good at: writing a solid headline. (Beth Mole, please report to collect your award.)
And headline writing is hard! It's a task with lots of constraints—length being the biggest (Ars headlines are limited to 70 characters), but nowhere near the only one. It is a challenge to cram into a small space enough information to accurately and adequately tease a story, while also including all the things you have to put into a headline (the traditional "who, what, where, when, why, and how many" collection of facts). Some of the elements are dynamic—a "who" or a "what" with a particularly long name that eats up the character count can really throw a wrench into things.
Plus, we know from experience that Ars readers do not like clickbait and will fill up the comments section with derision when they think they see it. We also know that there are some things that people will click on without fail. And we also know that regardless of the topic, some headlines result in more people clicking on them than others. (Is this clickbait? There's a philosophical argument there, but the primary thing that separates "a headline everyone wants to click on" from "clickbait" is the headline's honesty—does the story beneath the headline fully deliver on the headline's promise?)
Regardless, we know that some headlines are more effective than others because we do A/B testing of headlines. Every Ars article starts with two possible headlines assigned to it, and then the site presents both alternatives on the home page for a short period to see which one pulls in more traffic.
There have been a few studies done by data scientists with much more experience in data modeling and machine learning that have looked into what distinguishes "clickbait" headlines (ones designed strictly for getting large numbers of people to click through to an article) from "good" headlines (ones that actually summarize the articles behind them effectively and don't make you write lengthy complaints about the headlines on Twitter or in the comments). But these studies have been focused on understanding the content of the headlines rather than how many actual clicks they get.
To get a picture of what readers appear to like in a headline—and to try to understand how to write better headlines for the Ars audience—I grabbed a set of 500 of the most quickly clicked Ars headlines from the past five years and did some natural language processing on them. After stripping out the "stop words"—the most commonly occurring words in the English language that are typically not associated with the theme of the headline—I generated a word cloud to see what themes drive the most attention.
Here it is: the shape of Ars headlines.
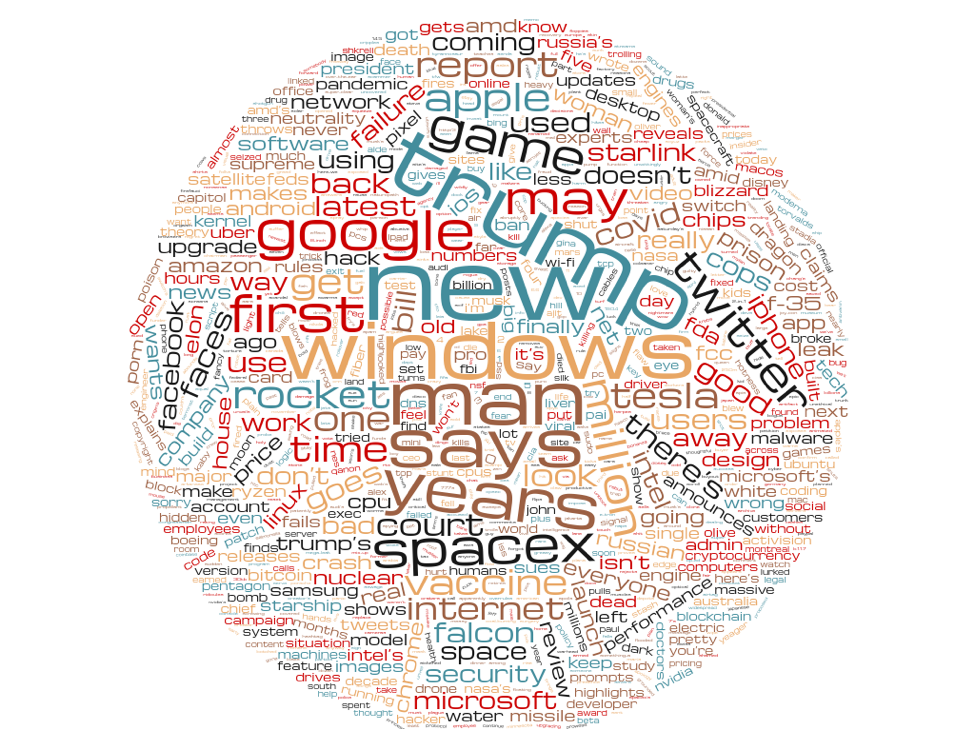
There is a whole lot of Trump in there—the last few years have included a lot of tech news involving the administration, so it's probably inevitable. But these are just the words from some of the winning headlines. I wanted to get a sense of what the difference between winning and losing headlines were. So I again took the corpus of all Ars headline pairs and split them between winners and losers. These are the winners:

And here are the losers:
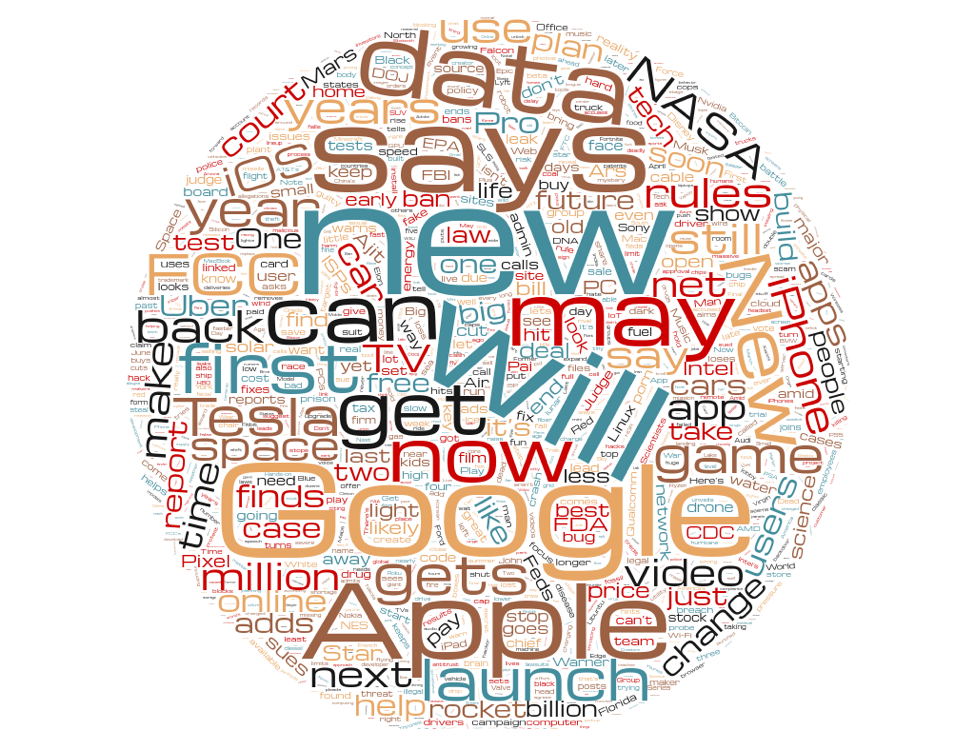
Remember that these headlines were written for the exact same stories as the winning headlines were. And for the most part, they use the same words—with some notable differences. There's a whole lot less "Trump" in the losing headlines. "Million" is heavily favored in winning headlines, but somewhat less so in losing ones. And the word "may"—a pretty indecisive headline word—is found more frequently in losing headlines than winning ones.
This is interesting information, but it doesn't in itself help predict whether a headline for any given story will be successful. Would it be possible to use ML to predict whether a headline would get more or fewer clicks? Could we use the accumulated wisdom of Ars readers to make a black box that could predict which headlines would be more successful?
Hell if I know, but we're going to try.
All this brings us to where we are now: Ars has given me data on over 5,500 headline tests over the past four years—11,000 headlines, each with their rate of click-throughs. My mission is to build a machine learning model that can calculate what makes a good Ars headline. And by "good," I mean one that appeals to you, dear Ars reader. To accomplish this, I have been given a small budget for Amazon Web Services compute resources and a month of nights and weekends (I have a day job, after all). No problem, right?
Before I started hunting Stack Exchange and various Git sites for magical solutions, however, I wanted to ground myself in what's possible with ML and look at what more talented people than I have already done with it. This research is as much of a roadmap for potential solutions as it is a source of inspiration.
Houston, we have a problem
The first rule of ML is knowing what kind of ML problem you're trying to solve and the types of models that apply to it. Some of that is governed by the data itself, and some of it is governed by how much of it you can manage to classify beforehand.
Some of the most common machine learning applications fall into the following categories:
- Binary classification: It either wins or loses, like our headlines.
- Multi-class classification: There are multiple groups that the inputs can fall into in various dimensions—either ones we've predetermined, or ones that the ML will discover while processing the learning data.
- Regression: There are multiple variables of inputs, and the goal is to predict something based on their relationship. This often is used for streams of data, such as stock market activity, to predict trends.
- Entity recognition: A model extracts phrases and words that are names of people, places, or things from a body of text using natural language processing.
- Summarization: A model extracts the gist of a body of text and creates a summary of it—so, like writing a headline.
A significant number of ML applications depend on what's referred to as supervised learning—cases in which a significant amount of data is available that's already been categorized. For example, one of AWS Sagemaker's tutorials is built on a published dataset based on financial product marketing—the details of the offer, the individuals the offers were made to, and the outcome are all available from a data dump. All the machine learning process has to do is connect the dots between which variables lead to a yes or a no.
Sometimes, getting enough pre-labeled data isn't possible. Building a library of images put into multiple categories, for example—floofy cat, non-floofy cat, floofy non-cat, non-floofy non-cat—would be expensive from a time and data storage perspective.
In situations like these, there are a few options. The first is unsupervised machine learning—the ML system uses the data itself to create groups, which can later be labeled. An in-between method called "semi-supervised machine learning" uses a smaller set of training data to set up the initial model, and then the model guesses at how to classify additional content, grouping data that seems similar.
A method called "reinforcement" is often used to tune the data from unsupervised and semi-supervised learning algorithms. This is sort of after-the-fact supervised learning—and if you’ve ever used an image CAPTCHA, you've participated in someone's reinforcement process. Apple's Photos app also uses reinforcement to tune its image recognition.
Our headline problem is (I'm hoping) a supervised learning problem: we have headlines, and we have known outcomes. The question is whether we have enough data between the two to build a model—or if there is any hidden statistical correlation at all that can be found in which headlines win A/B tests. There's also the small matter of what kind of ML approaches we want to use to do the learning.
Is that data or a ransom note?
Headlines are text, but our problem is not a typical text processing problem. Machine learning is often used for sentiment detection (looking for words that reflect a positive or negative predisposition toward a product, organization, or person), to detect what a story is about (based on word frequency or the structure of its contents), or for translation tasks. Google Translate is an example of a machine learning system that is constantly being guided in learning by humans, modeling the relationship not just between words in different languages but in sentence structure and grammar.
But here, the one thing we want to ignore, frankly, is what the text is about—we don't particularly care about its sentiment. In this case, the data is text strings (the headlines) and a set of metrics associated with them that are distilled down to a click-through rate (the fraction of the times an article headline was shown to an Ars reader that the reader clicked through to the story). The headline with the higher click-through rate wins the test.
What we're looking for is some hidden structure within these headlines that makes them work better or worse—specifically, what is different about headlines that win the test from headlines that lose? The data suggests that there is a qualitative difference between them, because all of the winning headlines in our data set won decisively.
Or, maybe there isn't a consistent enough reason for headlines winning or losing. Maybe everything is random and this is just a wild goose chase. There's only one way to find out!
The work ahead
I've already begun the first step in my descent into ML hell: doing the data preparation. Next week, I'll describe my data preprocessing exploits and the initial fruits of that labor. Then, I'll begin testing various approaches for building an ML model, seeking something with a higher accuracy rate than a coin flip (or a dice roll).
In the third episode of this experiment, I'll be trying to tune the resulting model or models and (with any luck) testing them against additional real-world headline tests to see how well the predictions the models make hold up. If all goes well, by our final installment, we'll have a deployable model that I'll have Ars staffers use to pre-test their headlines—and we can see if we can make accurate predictions about which headlines will end up being the final ones.
If all does not go well, then—well, you'll all have a front-row seat to a demonstration of how not to do machine learning. At the end of the day, you'll have learned at least what the tools look like, and I will have mastered all there is to master in regard to Jupyter notebooks and AWS console tricks and other things that might help you successfully deploy your own, much more well-reasoned and important machine learning-based application.
Either way, it should at least be entertaining. And if we can get a good robo-headline attached, maybe some new readers will find this experiment, too.
"machine" - Google News
July 13, 2021 at 10:00PM
https://ift.tt/3wH3oDg
Is our machine learning? Ars takes a dip into artificial intelligence - Ars Technica
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Is our machine learning? Ars takes a dip into artificial intelligence - Ars Technica"
Post a Comment