For example, of all the thousands of companies designing ICs around the world, only four were invited to describe their latest finished products at ISSCC 2022, and two of the four were machine learning processors: SambaNova with a 7nm chip with more than 40 billion transistors that can train a one trillion parameter natural language processing model in a quarter rack machine, and Tenstorrent with its ‘Wormhole’ neural network training processor delivering 430Tops from 771mm2 of 12nm CMOS – the other two invited ICs were the 52-core CPU Fujitsu designed for Fugaku, the world’s fastest (442Pflop) supercomputer, and a 7nm 55J/Thash Bitcoin mining asic from Intel.
At a rough count, including the two above, there were 23 papers concentrating on machine learning hardware.
Picking some highlights, Samsung has created a neural processing unit for a 4nm SoC that it is developing for use in mobile phones that can switch between a high-compute low-latency mode and ultra-low-power always-on mode.
Its reconfigurable data path supports integer and floating point operation, and a variety of neural networks, precisions and operations.
Peak energy benchmarks are 11.59Top/s/W at 0.55V for MobileNetEdgeTPU and 4.26Tflop/s/W at 0.55V for DeepLabV3 (FP16).
Another building block singled-out came from a joint academic venture between Tsinghua University and the University of California, Santa Barbara.
Again it has a reconfigurable data path supporting both floating-point and integer computation, but this time it is aimed at cloud use, and uses digital compute-in-memory processing with in-memory Booth multiplication, in-memory accumulation and exponent pre-alignment. The 28nm device achieves 29.2Tflop/s/W for BF16 calculations and and 36.5Top/s/W for 8bit integers.
Like Google and Facebook, Alibaba is also designing its own processors, and was singled-out at ISSCC 2022 for system-in-package techniques to get memory really close to logic in its machine learning processor: not using compute-in-memory but ‘process-near-memory’ to cut power losses in the interconnect.
It designed two matching 25 x 24mm die then hybrid-bonded them face-to-face using copper pads that deliver a combined bandwidth of 1.38Tbyte/s.
The top die is a 55nm 150MHz 1.1V DRAM, and the lower one has 25nm 300MHz 1.2V logic.
The Alibaba team claims >200x better energy efficiency compared to using off-chip memory, and a device performance of 184query/s/W (8bit integer).
These all pretty big AI processors, but the span at ISSCC this week is wide, extending from those, right down to a spiking recurrent neural network (RNN) processor from the University of Zurich and ETH Zurich.
Intended for hand gesture classification, keyword spotting and navigation, it is capable of both learning and inferring – the former over seconds at the cost of ~130μW and the latter in milliseconds for ~70μW.
Including 138kbyte if SRAM, the 28nm FDSoI CMOS chip occupies 0.45mm2.
Its designers have named it ReckOn, and made it available through GitHub with an open-source licence.
Another tiny machine learning processor came from National Tsing Hua University in Taiwan.
In this case a 128×128 image sensor has been built alongside an embedded convolutional neural network model with programmable weights on a 180nm cmos die.
The network uses mixed-mode processing – part digital and part analogue – to implement configurable feature extraction and on-chip image classification. Used for human face detection, for example, it is 93.6% accurate.
Power consumption is 80μW from an 800mV supply at 50frame/s, or 134μW at 250frame/s – the latter amounting to 34pJ/pixel/frame/s.
Machine learning has meant a renaissance for analogue computing, where it can save power when implementing, for example, a results accumulator.
US company Mythic revealed a NOR flash array at ISSCC 2022, used to implement analogue compute-in-memory for real-time video analytics.
Being analogue, efforts have to be made to maintain sufficient precision. In this case, for example, the analogue array gets temperature compensation through a sensor, a lookup-table and bias control.
Residual error exists between cells, which are handled through analogue-aware neural network training in the associated software development kit.
Peak performance from the 16 x 12mm 40nm die was, measured from 8 to 2bit precision, 16.6 to 59.3Top/s and 3.3 to 10.9Top/s/W for the system, or 5.2 to 18.5Top/s/W for the analogue array alone.
While detecting human poses, it achieved 90 inference/s while consuming 3.73W.
“This year’s submissions significantly push the state-of-the-art of efficiency and throughput numbers yet again, often by combining multiple enhancement techniques within a single chip, or multiple chiplets, implemented across a broad range of technology nodes,” said Marian Verhelst of the Katholieke Universiteit Leuven, who chairs the ISSCC machine learning committee. “The clever combination of sparsity, variable precision and in-memory computing technologies is continuing to enhance deep-learning processor efficiency and throughput.”
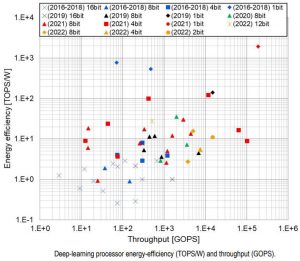
To compare machine learning processor developments over the last few years, ISSCC produced a throughput vs energy efficiency scatter plot (right).
Why doesn’t it show this years crop in a very good light compared with 2021?
“Keep in mind that these Top/s/W and Top/s specifications depend strongly on the level of integration of the chip, and on the particular neural network topologies being used,” cautions Verhelst, pointing out that the power-efficient compute arrays introduced in previous years are now being presented integrated into full processing systems.
As increasingly large, as well as small, networks are being implemented, with more or less system around them, “we believe that a common benchmarking methodology must be established which can properly account for the application context and provide proper translation between low-level and system-level performance metrics”, she said.
ISSCC 2022 is the 69th International Solid-State Circuits Conference, a conference which is arguably the world showcase for advances in on-chip circuit design and system-on-a-chip implementation. During the week-long conference, hundreds of selected and invited papers are presented, from the US, Asia and Europe.
ISSCC 2022 papers referred to above
- 21.1 SambaNova SN10 RDU: A 7nm dataflow architecture to accelerate software 2.0
- 21.4 The Wormhole AI training processor
- 15.1 A multi-mode 8k-MAC HW-utilization-aware neural processing unit with a unified multi-rrecision datapath in 4nm flagship mobile SoC
- 15.5 A 28nm 29.2Tflops/W BF16 and 36.5Tops/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration
- 29.1 184Qps/W 64Mb/mm2 3d logic-to-DRAM hybrid bonding with process-near-memory engine for recommendation
system - 29.4 ReckOn: A 28nm Sub-mm2 task-agnostic spiking recurrent neural network processor enabling on-chip learning over second-long timescales
https://ift.tt/6cRwvGo - 15.9 A 0.8V intelligent vision sensor with tiny convolutional neural network and programmable weights using
mixed-mode processing-in-sensor technique for image classification - 15.8 Analog matrix processor for edge AI real-time video analytics
Also see papers in Session 11, a collection of memory papers specialising in compute-in-memory
"machine" - Google News
February 22, 2022 at 11:37PM
https://ift.tt/CRfVFS1
ISSCC 2022: Machine learning processors - Electronics Weekly
"machine" - Google News
https://ift.tt/f67QpwS
https://ift.tt/qGEJ7Vl
Bagikan Berita Ini














0 Response to "ISSCC 2022: Machine learning processors - Electronics Weekly"
Post a Comment