We live in a time of unparalleled use of machine learning (ML), but it relies on one approach to training the models that are implemented in artificial neural networks (ANNs) — so named because they’re not neuromorphic. But other training approaches, some of which are more biomimetic than others, are being developed. The big question remains whether any of them will become commercially viable.
ML training frequently is divided into two camps — supervised and unsupervised. As it turns out, the divisions are not so clear-cut. The variety of approaches that exists defies neat pigeonholing. Yet the end goal remains training that is easier and uses far less energy than what we do today.
“The amount of computation for training is doubling every three to four months. That’s unsustainable,” said Geoffrey Burr, distinguished research staff member at IBM Research. While inference is making a push toward the edge, training remains a data-center activity specifically because it requires so much computing power.
Where we are today: gradient descent
“The one [training method] that everyone’s looking at is supervised learning,” said Elias Fallon, software engineering group director for the Custom IC & PCB Group at Cadence, referring to the approach in wide use today. “The key there is that I have labels.”
This means that, before a neural network — or “network” for short — is deployed, it goes through an extensive offline training process. That process proceeds by presenting a broad set of labeled samples to the network. The labels identify the features contained in the samples and serve to tell the network whether or not it made the right decision while it’s being trained.
Supervised training starts with a random model and then, through trial and error, tweaks the model until it gives acceptable results. For any given model, there’s no one unique “correct” or “best” model. Slight deviations in the training technique — ones as innocuous as changing the order of the training samples — will generate different models. And yet, as long as all the different models operate with the same accuracy, they are all equally valid.
An incorrect decision during training will be detected in the final layer of the network, which contains the percentage likelihood of each possible category. Because those values are numeric, the error can be calculated. At this point, the “gradient descent” algorithm determines how the weights would need to change in the next-to-last layer in order for the last layer to achieve the correct response. From that next-to-last layer, you then can move back another layer to see what would need to change in that layer in order for the next-to-last layer to be correct. This “back-propagation” continues until all weights have been changed.
After this process is done on the first sample, the network is correct only for that sample. Then the next sample is presented, and the process repeats. The intent is that, after a very large number of samples that are randomized and generalized well enough to be free of bias, the adjustments to the weights will be smaller and smaller with each succeeding sample, ultimately converging on a set of weights that let the network recognize new samples that it hasn’t seen before with acceptable accuracy.
“There’s lots of variation on the gradient-descent approach,” said Fallon. This training technique has seen enormous success for a wide range of applications, but its big downside is that it demands a huge amount of energy, and the calculations require enormous amounts of computation. For each sample, millions or billions of weights must be calculated, and there may be thousands of samples.
In addition, the gradient-descent approach to training bears no resemblance to what happens in animal brains. “Back-propagation is not biologically plausible,” said Chris Eliasmith, director of the Center for Theoretical Neuroscience at the University of Waterloo.
Peter van der Made, Brainchip CTO and founder, agreed. “Back-propagation is totally artificial and has no equivalent in biology. [It] may be useful in creating fixed features, but it cannot be used for real-time learning. Because of its successive approximation method, it needs millions of labeled samples to make a decision if the network is correct or not and to readjust its weights.”
It’s a convenient numerical approach, but it requires the ability to calculate the “descent” — essentially a derivative — in order to be effective. As far as we can tell, there’s no such parallel activity in the brain.
By itself, that’s not a huge problem. If it works, then it works. But the search for a more biomimetic approach continues because the brain can do all of this with far, far less energy than we require in machines. Therefore, researchers remain tantalized by the possibilities of doing more with less energy.
In addition, labeling data sets can be extremely expensive and time-consuming. This can set up a high barrier in some fields, where labeling data may be less viable than it is with images — like with proteins. Training techniques that don’t require labeling promise to be more accessible than current techniques.
Unsupervised learning
The effort of labeling samples can be removed if instead we can perform unsupervised learning. Such learning still requires samples, but those samples will have no labels — and therefore, there is no one specifically saying what the right answer is. “The big distinction is whether I have labeled outputs or not,” said Fallon.
With this approach, algorithms attempt to find commonalities in the data sets using techniques like clustering. As Fallon noted, this amounts to, “Let’s figure out how to group things.” These groupings perform like inferred labels. While this may sound less satisfying than the rigor of saying, “That is a cat,” in the end, the category of “cats” is nothing more than a cluster of images that share the characteristics of a cat. Of course, we like to put names on categories, which the manual labeling process permits. But unsupervised clustering may result in naturally occurring groupings that may not correspond to anything with a simple name. And some groupings may have more value than others.
The clustering can be assisted by what’s referred to as “semi-supervised” learning, which mixes the approaches of both unsupervised and supervised learning. So there will be a few samples that are labeled, but many more that are not. The labeled samples can be thought of as resembling a nucleating site in crystallization — it gives the unlabeled samples some examples around which the clustering can proceed.
“Auto-encoders” can provide a way to effectively label or characterize features in unlabeled samples. The idea is that a network tries to discover categories and reduce them to avoid noise or other irrelevant aspects of the data. The correctness of that reduction is checked by feeding it into the reverse of the generating model to see if it can correctly reconstruct the original sample. This would appear to be akin to taking a phrase, running it through a language translator, and then taking the translated result and running it back through a reverse translator to see if the final result matches the original.
In general, unsupervised learning is a very broad category with lots of possibilities, but there doesn’t appear to be a clear path yet toward commercial viability.
Reinforcement learning
Yet a third category of training is “reinforcement learning,” and it already is seeing limited commercial use. It’s more visible in algorithms trained to win games like Go. It operates through a reward system, with good decisions reinforced and bad ones discouraged. It’s not a new thing, but it’s also not well established yet. It gets its own category since, as Cadence’s Fallon noted, “[Reinforcement] doesn’t really fall into the supervised or unsupervised [distinction].”
Eliasmith provided a simple game example where you’re trying to find a “correct” cell for a marker to occupy, with the marker starting in some random other cell. The first moves are necessarily random, and hitting the reward comes by accident. But once rewarded, you mark nearby cells as being close to the right place so that you have a hint the next time that you’re in the neighborhood. From there, other cells can be marked in a manner similar to leaving breadcrumbs to find your way to the correct position more easily in the future.
It’s not a perfect reward system, however. “[A reward] may not provide the right answer, but it’s a push in the right direction,” said Eliasmith.


Fig. 1: Reinforcement learning uses feedback from the environment to reward or punish a decision. Source: Megajuice
The environment matters, however. “[Reinforcement] can be useful if you have a notion of the environment and can provide a positive or negative reward,” said Fallon. The big challenge here is the reward system. This system operates at a high level, so what constitutes a reward can vary widely, and it will be very application-dependent.
“Reward learning is derived from animal behavior,” said Brainchip’s van der Made. “An animal learns something and is given a reward, such as food. This reinforces the behavior, and the animal has learned that the way to get food is to perform the same trick. In computer hardware, this method was used to reinforce learning, by rewarding or punishing the learning algorithm. But there are some problems with this method. The reward comes after the action, sometimes way after the action, and the algorithm has to remember which action is associated with which reward or punishment. And how can you define the higher concept of ‘reward’ to an abstract, low-level algorithm?”
Eliasmith refers to the first criticism that van der Made raised as the “credit assignment problem.” In a game of Go, for instance, every individual move leads either to success or to failure. It’s easy to determine whether the final move should be rewarded, but what about the first move and all of the intermediate ones? Which of those were instrumental to achieving a win, and which made the win harder — or even resulted in a loss? There may be dozens or hundreds of moves, each of which contributes to or against a win, with the win or loss being deferred until the final move. How do you reward those early moves?
For this reason, such training may require a very high number of simulated runs in order to have a statistical basis for deciding which moves tend to be beneficial overall. “This has been successful only if you can run billions of games,” said Fallon.
“There are a million ways people try to deal with this,” said Eliasmith. Even so, we should not expect perfection in assigning rewards and punishments. “Biology hasn’t solved it perfectly.”
There are daily examples of humans and other animals mis-associating cause and effect. But in general, reinforcement learning may end up being a mix of offline and online training. This is particularly true for robotics applications, where you can’t think of every possible scenario during offline training. Incremental learning must be possible as the machines go through their paces and encounter unforeseen situations.
Reinforcement learning tends to be good at solving control problems — such as robotics. Google used it for its cooling and saved 40% on its energy bill. This approach shows some promise for commercial viability.
Hebbian learning and STDP
While the credit assignment problem may have solutions for some applications, the high-level nature of reinforcement learning remains. Rewarding a parrot with a cracker operates at a level far above that of neurons passing neurotransmitters through a synaptic gap. Ultimately, animal brains learn at that low level, so some researchers focus on this level of abstraction.
Donald Hebb is credited with the notion that, “Neurons that fire together wire together,” although he didn’t literally coin that phrase — just the notion. “This is not exactly what he said, but it’s what we remember,” said Eliasmith. The idea is that, given two neurons, if one fires before the other, a link should be reinforced. If one fires after the other, the link should be weakened. How close in time the two firings are can affect the strength of the reinforcement or weakening. “This is understood to be closer to how neurons actually learn things,” said Fallon.
“At the lower level, neurons in the brain modify their synaptic weights (learning) by a process known as Spike Time Dependent Plasticity (STDP),” said van der Made. “This is a mouthful for a simple process that was made complex by mathematics. To put it more simply, when an input occurs before an output, the synapse weight is increased — while if the input occurs after the output, the synapse weight is decreased. In this way a neuron learns to respond to particular patterns that occur in the input, while other patterns are depressed. With many neurons learning different patterns, it is possible to learn very complex sets of patterns.” This specifically codifies a timing relationship between neurons and can result in temporal coding within spiking neural networks (SNNs).
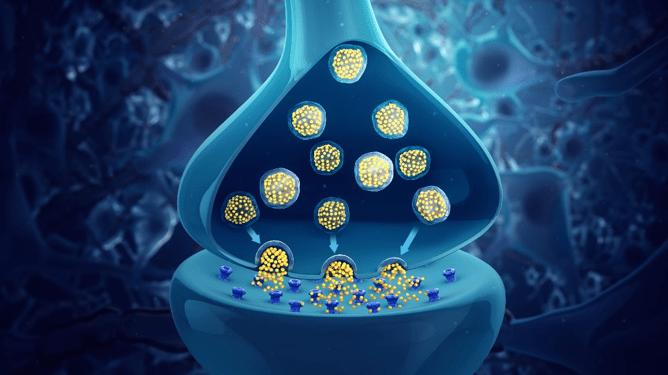
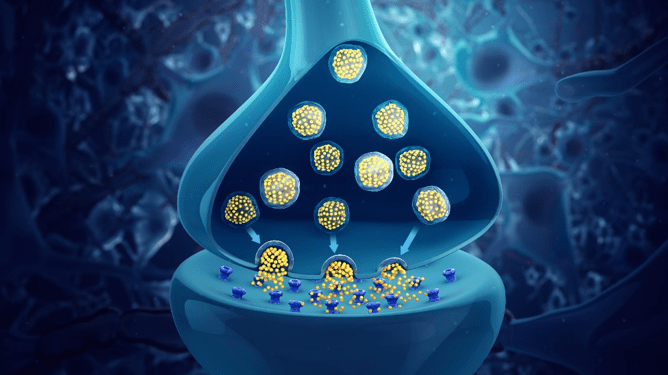
Fig. 2: STDP attempts to mimic more closely the low-level behavior of a biological synapse, where neurons “fire” neurotransmitters across the synaptic cleft. The timing of this firing can reinforce or suppress a connection. Source: Scientific Animations on Wikipedia.
STDP allows for training, either supervised or unsupervised, with fewer samples than we require today. Brainchip has leveraged some of the ideas in its SNN, which it uses to provide incremental-training opportunities for deployed chips. Additional vision categories can be achieved with as few as one training sample.
“The combination of fixed features and STDP learning — which occurs instantly and does not need more than one sample — opens interesting possibilities,” said van der Made. “It can learn to recognize new objects instantly (with no reward).”
University of Waterloo’s Eliasmith observed that incremental learning isn’t new. As an example, he noted that Google came up with the BERT neural network, complete with weights, and made it openly available. Others started from that point and added their own additional layers for incremental learning beyond what Google had released.
Van der Made also pointed out that, unlike current ANNs, the brain leverages feedback as it operates. “The brain contains many feedback connections. Even STDP learning works by feeding the timing difference between the inputs and output of a neuron back to adjust synaptic weights.”
But he distinguishes this from behavioral rewards. “Higher-level feedback occurs not only through nerve fibers, but also through the environment,” he said. “We learn from our mistakes and also from our successes. To apply that higher-level learning at a low level is a mistake.”
Other structural elements to the brain have not yet been explored in machines, said van der Made. “This process [STDP] is enhanced by the columnar structure of the brain, which allows the columns to learn relationships between patterns. I believe that the organization, or rather little differences in organization, make the difference between individuals who learn rapidly versus individuals who learn slowly. We can see this in the extreme in savants. The columnar organization of the brain has been completely ignored in artificial neural networks.”
Many other approaches and variants are being tried in research laboratories, most of which are far from a commercial solution. “Some of these other techniques might be better when there’s less data and lower power requirements,” noted Fallon. But an attempt to find one best training technique is likely to fail due to what Eliasmith referred to as the “No free lunch” theorem: Every learning mode will be good at some problems and not good at others.
"machine" - Google News
July 01, 2020 at 02:06PM
https://ift.tt/2BRgXth
Are Better Machine Training Approaches Ahead? - SemiEngineering
"machine" - Google News
https://ift.tt/2VUJ7uS
https://ift.tt/2SvsFPt
Bagikan Berita Ini














0 Response to "Are Better Machine Training Approaches Ahead? - SemiEngineering"
Post a Comment